无限空间的幻觉
虚拟内存的核心在于创造一种幻觉——拥有比实际存在更多的内存。但这个魔术是如何实现的呢?
进入:页表
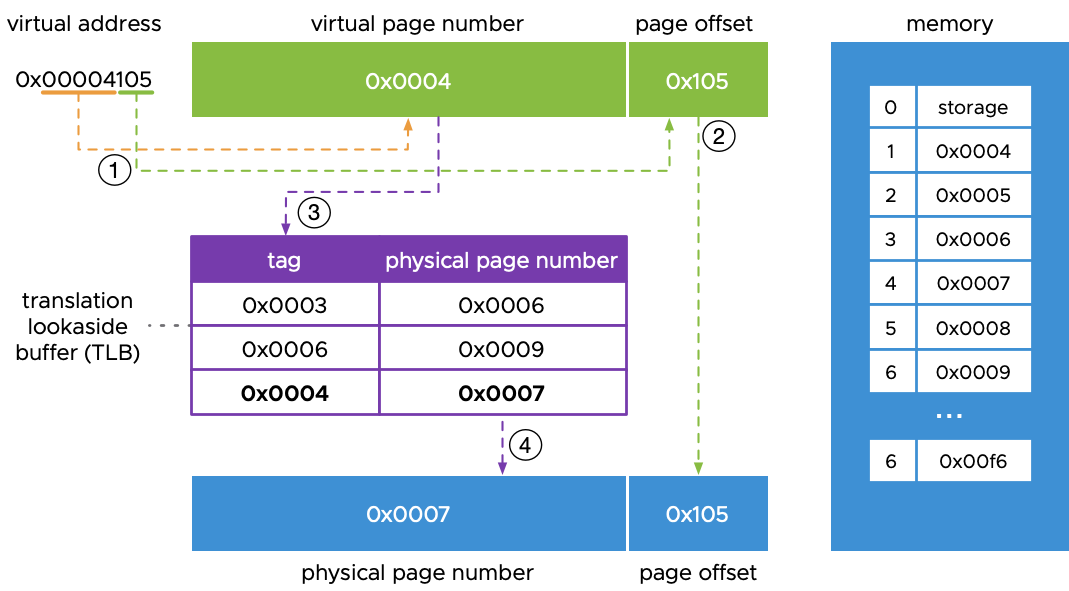
页表是内存管理中不为人知的英雄。它们充当地图,将虚拟地址的广阔空间与物理内存的有限领域进行转换。以下是它们工作原理的简化视图:
struct PageTableEntry {
uint32_t physical_page_number : 20;
uint32_t present : 1;
uint32_t writable : 1;
uint32_t user_accessible : 1;
uint32_t write_through : 1;
uint32_t cache_disabled : 1;
uint32_t accessed : 1;
uint32_t dirty : 1;
uint32_t reserved : 5;
};
页表中的每个条目对应于虚拟内存中的一页,通常大小为4KB。当程序尝试访问内存时,CPU使用页表来查找该内存在物理RAM中的实际位置。
翻译的代价
但问题在于:通过页表翻译地址的速度很慢。非常慢。我们说的是“看油漆干”的慢速。对于每次内存访问,CPU需要执行多次内存查找才能找出实际数据存储的位置。这时,我们的下一个角色登场了……
TLB:地址翻译的速度魔鬼
翻译后备缓冲区(TLB)是我们虚拟内存引擎中的氮气加速器。它们是小而快速的缓存,存储最近从虚拟地址到物理地址的翻译。
可以把TLB想象成你大脑中的短期记忆。与其每次想去某个地方时都拿出地图(页表),不如在最近去过的地方时直接记住路线。
TLB如何施展魔法
以下是TLB可能如何操作的简化伪代码:
def access_memory(virtual_address):
if virtual_address in TLB:
physical_address = TLB[virtual_address]
return fetch_data(physical_address)
else:
physical_address = page_table_lookup(virtual_address)
TLB[virtual_address] = physical_address
return fetch_data(physical_address)
这种简单的机制大大加快了内存访问速度。事实上,现代CPU的TLB命中率可以超过99%,这意味着100次内存访问中有99次不需要触碰慢速的页表!
黑暗面:TLB未命中和抖动
但如果TLB找不到翻译会怎样?这被称为TLB未命中,就像在周五下午4:59发现生产代码中的一个bug一样有趣。
当TLB未命中发生时,CPU必须:
- 遍历页表以找到正确的翻译
- 用新翻译更新TLB
- 重试内存访问
这个过程可能非常慢,尤其是当它频繁发生时。当你的程序开始经历大量TLB未命中时,性能可能会像铅气球一样迅速下降。这种情况被称为TLB抖动,对于性能敏感的应用程序来说是噩梦。
避免抖动
为了让你的程序顺利运行,请考虑以下建议:
- 在适当时使用更大的页面大小(Linux中的大页面,Windows中的大页面)
- 优化内存访问模式以提高局部性
- 注意你的工作集大小
记住:一个快乐的TLB意味着一个高效的程序!
超越基础:高级虚拟内存技术
当我们深入虚拟内存的兔子洞时,我们会遇到一些迷人的高级技术:
倒置页表
传统的页表可能会消耗大量内存,尤其是在64位系统中。倒置页表颠覆了这一概念,使用哈希表将物理页面映射到虚拟地址。这可以显著减少页表的内存开销,但可能会导致查找时间更长。
多级页表
为了处理现代系统的庞大地址空间,多级页表将翻译过程分解为多个阶段。例如,一个典型的x86-64系统可能使用四级页表:
CR3 → PML4 → PDP → PD → PT → Physical Page
这种分层方法允许高效的内存使用和灵活的内存管理。
ASID:无需刷新上下文切换
地址空间标识符(ASID)是一些架构用来避免在每次上下文切换时刷新TLB的巧妙技巧。通过用ASID标记TLB条目,CPU可以同时保留多个进程的翻译在TLB中。
struct TLBEntry {
uint64_t virtual_page_number;
uint64_t physical_page_number;
uint16_t asid;
// ... other flags
};
这可以显著提高频繁上下文切换系统的性能。
虚拟内存的未来
随着我们推动计算的边界,虚拟内存继续发展。一些令人兴奋的发展包括:
- 异构内存管理:随着结合不同类型内存(DRAM、NVRAM、HBM)的系统的兴起,虚拟内存系统正在适应以高效管理这些多样化的资源。
- 硬件辅助页表遍历:一些现代CPU包括专用硬件用于遍历页表,进一步减少TLB未命中的性能影响。
- 机器学习驱动的预取:研究人员正在探索使用ML技术来预测内存访问模式并将页面预取到TLB中。
总结:现代计算的无形支柱
虚拟内存,通过页表和TLB的复杂舞蹈,构成了现代计算的无形支柱。这是计算机科学家和工程师的智慧结晶,将碎片化的物理资源幻化为广阔的连续内存空间。
下次你的程序运行时,请想一想在幕后工作的复杂机制,它将你的虚拟地址无忧无虑地翻译成物理现实。记住,在虚拟内存的世界中,没有什么是看起来那样的——但这正是它如此强大的原因。
“在计算机科学中,我们站在巨人的肩膀上——而那些巨人则站在一个非常聪明的虚拟内存实现上。” - 匿名比特驯服者
现在,勇敢地分配内存吧——你的虚拟内存系统会支持你的!