分布式困境
在我们进入解决方案之前,先来了解一下问题。在分布式系统中,确保消息的顺序就像赶猫一样——理论上可行,但实际上具有挑战性。为什么呢?因为在分布式世界中,时间不是绝对的,网络延迟不可预测,而墨菲定律总是发挥作用。
无序的危险
- 数据不一致
- 业务逻辑中断
- 用户不满(经理更不满)
- 那种你应该选择其他职业的隐约感觉
但别担心!这就是我们的动态二人组登场的地方:Kafka 和 Zookeeper。
登场:消息传递超级英雄 Kafka
Apache Kafka 不只是另一个消息系统;它是发布/订阅框架中的超人。诞生于 LinkedIn 的深处,并在全球生产环境中经过实战考验,Kafka 在消息排序方面带来了强大的火力。
Kafka 的排序秘密武器
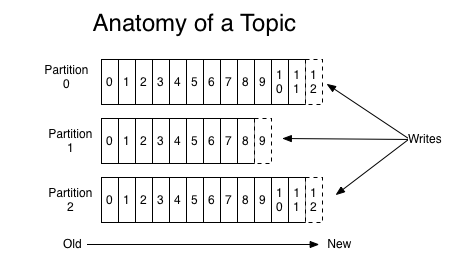
- 分区:Kafka 的分区是保持顺序的秘密武器。分区内的消息保证有序。
- 键:通过使用键,可以确保相关消息总是落在同一分区,保持它们的相对顺序。
- 偏移量:分区中的每条消息都有一个唯一的递增偏移量,提供了事件的清晰时间线。
让我们来看一个在 Kafka 中使用键生成消息的简单示例:
ProducerRecord record = new ProducerRecord<>("my-topic",
"message-key",
"Hello, ordered world!");
producer.send(record);
通过一致地使用 "message-key",可以确保所有这些消息最终落在同一分区,保持它们的顺序。
Zookeeper:协调的无名英雄
虽然 Kafka 吸引了所有的目光,但 Zookeeper 在幕后默默工作,确保一切顺利进行。可以把 Zookeeper 想象成你分布式表演的舞台经理——它可能不会获得观众的起立鼓掌,但没有它,演出就无法继续。
Zookeeper 如何支持顺序
- 管理 Kafka 代理元数据
- 处理分区的领导者选举
- 维护配置信息
- 提供分布式同步
Zookeeper 在维护顺序方面的作用更为间接但至关重要。通过管理 Kafka 集群的元数据并确保顺利运行,它为 Kafka 的排序保证提供了稳定的基础。
确保可靠排序的实用技巧
现在我们了解了工具,让我们看看一些确保分布式系统中可靠消息排序的实用技巧:
- 设计时考虑分区:合理组织数据并选择键,以利用 Kafka 的分区实现自然排序。
- 使用单分区主题实现严格排序:如果全局排序至关重要,可以考虑使用单个分区,但要注意吞吐量限制。
- 实现幂等消费者:即使有排序保证,也要设计消费者以优雅地处理可能的重复或无序消息。
- 监控和调整 Zookeeper:配置良好的 Zookeeper 集群对 Kafka 的性能至关重要。定期监控和调整可以防止许多排序问题的发生。
警告:CAP 定理再次来袭
"在分布式系统中,你最多只能拥有三者中的两个:一致性、可用性和分区容错性。"
请记住,虽然 Kafka 和 Zookeeper 提供了强大的消息排序工具,但它们不是魔法棒。在分布式系统中,总会有权衡。大规模系统中的严格全局排序可能会影响性能和可用性。始终考虑你的具体用例和需求。
综合运用
让我们看看如何使用 Kafka 和 Zookeeper 确保分布式系统中事件的有序处理的更全面示例:
public class OrderedEventProcessor {
private final KafkaConsumer consumer;
private final KafkaProducer producer;
public OrderedEventProcessor(String bootstrapServers, String zookeeperConnect) {
Properties props = new Properties();
props.put("bootstrap.servers", bootstrapServers);
props.put("group.id", "ordered-event-processor");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "earliest");
props.put("enable.auto.commit", "false");
this.consumer = new KafkaConsumer<>(props);
this.producer = new KafkaProducer<>(props);
}
public void processEvents() {
consumer.subscribe(Arrays.asList("input-topic"));
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord record : records) {
String key = record.key();
String value = record.value();
// 处理事件
String processedValue = processEvent(value);
// 将处理后的事件生成到输出主题
ProducerRecord outputRecord =
new ProducerRecord<>("output-topic", key, processedValue);
producer.send(outputRecord);
}
// 手动提交偏移量以确保至少一次处理
consumer.commitSync();
}
}
private String processEvent(String event) {
// 你的事件处理逻辑
return "Processed: " + event;
}
public static void main(String[] args) {
String bootstrapServers = "localhost:9092";
String zookeeperConnect = "localhost:2181";
OrderedEventProcessor processor = new OrderedEventProcessor(bootstrapServers, zookeeperConnect);
processor.processEvents();
}
}
在这个例子中,我们使用 Kafka 的消费者组来并行化处理,同时保持分区内的顺序。使用键确保相关事件按顺序处理,手动提交偏移量提供至少一次处理语义。
结论:掌握排序的艺术
在分布式系统中实现可靠的消息排序并非易事,但有了 Kafka 和 Zookeeper,你就有能力应对这一挑战。记住:
- 战略性地使用 Kafka 的分区和键
- 让 Zookeeper 处理幕后协调
- 根据排序要求设计系统
- 始终准备好应对偶尔的故障——分布式系统是复杂的
通过掌握这些概念和工具,你将能够构建稳健、有序且可靠的分布式系统。谁知道呢,也许你最终会发现自己更喜欢这个,而不是养山羊!
现在去吧,愿你的消息总是按预期顺序到达。编码愉快!