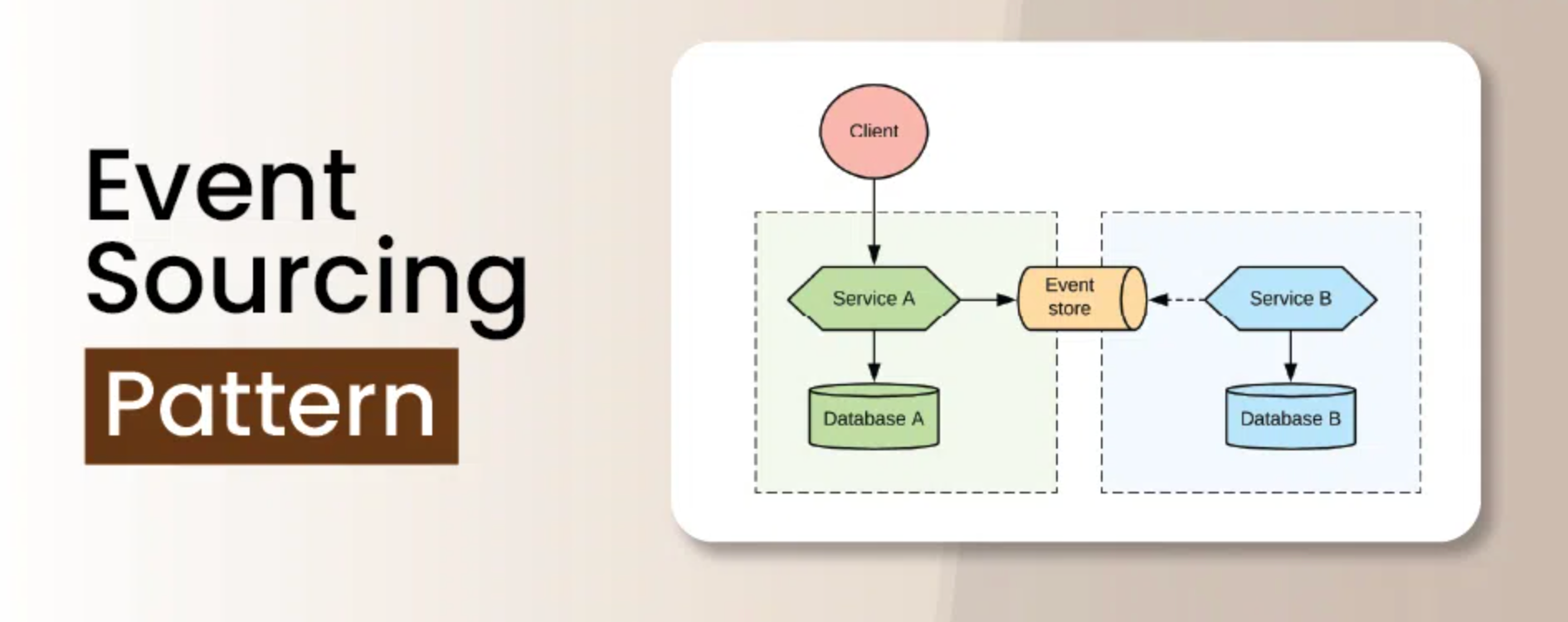
在我们深入探讨之前,让我们回顾一下为什么我们最初会被事件溯源所吸引:
- 完整的审计记录?没问题。
- 重建过去状态的能力?没问题。
- 灵活演变领域模型的能力?没问题。
- 可扩展性和性能优势?双重确认。
这一切听起来好得令人难以置信。剧透:确实如此。
设置:我们的库存管理系统
我们的系统被设计用于处理多个仓库中的数百万个SKU。我们选择事件溯源来维护每次库存移动、价格变动和商品属性更新的精确历史记录。事件存储是我们的真实来源,投影提供了快速查询的当前状态。
以下是我们事件结构的简化版本:
{
"eventId": "e123456-7890-abcd-ef12-34567890abcd",
"eventType": "StockAdded",
"aggregateId": "SKU123456",
"timestamp": "2023-04-01T12:00:00Z",
"data": {
"quantity": 100,
"warehouseId": "WH001"
},
"version": 1
}看起来很简单,对吧?哦,我们是多么天真。
揭示:事件版本化的陷阱
我们的第一个重大问题出现在我们需要更新StockAdded事件以包含reason字段时。我们以为这很简单。我们只需增加版本号并添加迁移策略。能出什么问题呢?
一切。所有事情都可能出错。
教训1:像生命依赖于它一样为你的事件版本化
我们犯了一个经典错误:为所有事件使用单一版本号。这意味着当我们更新StockAdded时,我们无意中破坏了所有其他事件的处理。
我们应该这样做:
{
"eventType": "StockAdded",
"eventVersion": 2,
"data": {
"quantity": 100,
"warehouseId": "WH001",
"reason": "Initial stock"
}
}通过独立版本化每种事件类型,我们本可以避免导致系统崩溃的多米诺效应。
教训2:迁移不是可选的
我们最初认为可以通过在事件处理程序中处理两个版本来解决问题。大错特错。随着系统的增长,这种方法变得不可持续。
相反,我们应该实施一个强大的迁移策略:
def migrate_stock_added_v1_to_v2(event):
if event['eventVersion'] == 1:
event['data']['reason'] = 'Legacy import'
event['eventVersion'] = 2
return event
# 从事件存储中读取时应用迁移
events = [migrate_stock_added_v1_to_v2(e) for e in read_events()]
快照故事:当优化适得其反
随着我们的事件存储增长,重建投影变得异常缓慢。于是我们引入了快照:本以为是救世主,却成了另一个噩梦。
教训3:快照频率是一个微妙的平衡
我们最初每100个事件创建一次快照。这在我们遇到交易激增之前运作良好,导致快照创建滞后,投影变得越来越过时。
解决方案?自适应快照频率:
def should_create_snapshot(aggregate):
time_since_last_snapshot = current_time() - aggregate.last_snapshot_time
events_since_last_snapshot = aggregate.event_count - aggregate.last_snapshot_event_count
return (time_since_last_snapshot > MAX_TIME_BETWEEN_SNAPSHOTS or
events_since_last_snapshot > MAX_EVENTS_BETWEEN_SNAPSHOTS)
教训4:快照也需要版本化
我们忘记了为快照版本化。当我们更改聚合结构时,所有事情都失控了。旧的快照变得不兼容,我们无法重建投影。
解决方法?为快照版本化并提供升级路径:
def upgrade_snapshot(snapshot):
if snapshot['version'] == 1:
snapshot['data']['newField'] = calculate_new_field(snapshot['data'])
snapshot['version'] = 2
return snapshot
# 加载快照时使用
snapshot = upgrade_snapshot(load_snapshot(aggregate_id))
腐败难题:当你的真实来源撒谎
压垮我们的最后一根稻草是事件存储的腐败。网络问题、事件存储中的一个错误以及一些过于激进的错误处理共同导致了事件的重复和丢失。
教训5:信任,但要验证
我们盲目地信任我们的事件存储。相反,我们应该实施校验和定期完整性检查:
def verify_event_integrity(event):
expected_hash = calculate_hash(event['data'])
return event['hash'] == expected_hash
def perform_integrity_check():
for event in read_all_events():
if not verify_event_integrity(event):
raise IntegrityError(f"Corrupt event detected: {event['eventId']}")
教训6:实施恢复策略
当腐败发生时(它会发生),你需要一种恢复的方法。我们没有,结果付出了惨重的代价。我们应该这样做:
- 维护一个单独的、仅追加的所有传入命令的日志。
- 实施一个对比命令日志和事件存储的对账过程。
- 创建一个恢复过程以重放丢失的事件或删除重复事件。
def reconcile_events():
command_log = read_command_log()
event_store = read_event_store()
for command in command_log:
if not event_exists_for_command(command, event_store):
replay_command(command)
for event in event_store:
if is_duplicate_event(event, event_store):
remove_duplicate_event(event)
凤凰涅槃:以韧性重建
经过无数个不眠之夜和大量的咖啡,我们终于稳定了系统。以下是帮助我们从灰烬中重生的关键要点:
- 事件版本化不是可选的——从第一天开始就要做。
- 为事件和快照实施强大的迁移策略。
- 自适应快照创建平衡了性能和一致性。
- 不要信任任何东西——在每个层级实施完整性检查。
- 在需要之前制定明确的恢复策略。
- 广泛的测试,包括混沌工程,可以拯救你的系统。
结论:事件溯源的双刃剑
事件溯源很强大,但也很复杂。它不是万能的,需要仔细考虑和强大的工程实践才能在生产中成功。
记住,能力越大,责任越大——在事件溯源的情况下,意味着很多不眠之夜。但有了这些经验教训,你现在更有准备去应对事件溯源的挑战。
现在,请原谅我,我需要处理一些创伤后应激障碍。有人知道专门治疗事件溯源创伤的好治疗师吗?
“在事件溯源中,就像在生活中一样,不是要避免失败,而是要优雅地失败并更强大地恢复。”
进一步阅读
- EventStore - 为事件溯源构建的流数据库
- Greg Young的m-r项目 - 一个简单的CQRS和事件溯源实现
- Martin Fowler关于事件溯源的文章
你是否也与事件溯源的恶魔斗争过?在评论中分享你的战斗故事——毕竟,痛苦喜欢陪伴!