让我们来看看什么是布隆过滤器:
- 一种空间高效的概率数据结构
- 用于测试元素是否属于集合
- 可能出现假阳性,但绝不会出现假阴性
- 非常适合减少不必要的查找
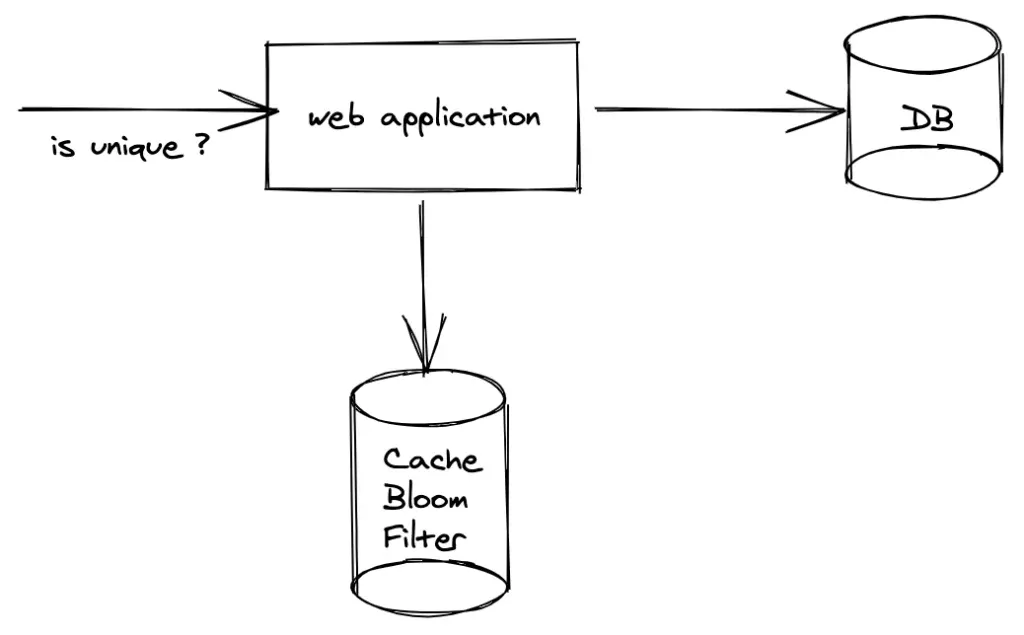
简单来说,它就像是你数据库的保镖。在真正让你进入数据库之前,它会快速检查某个东西可能在里面。
引入 Redis:快速的助手
为什么选择 Redis?因为它快。快到你眨眼就错过。将布隆过滤器与 Redis 结合,就像给你已经很快的赛车装上火箭。
设置你的 Redis 布隆过滤器
首先,你需要安装 RedisBloom 模块。如果你使用 Docker,只需执行以下命令:
docker run -p 6379:6379 redislabs/rebloom:latest现在,让我们使用 redis-py 库在 Python 中实现一个基本的布隆过滤器:
import redis
from redisbloom.client import Client
# 连接到 Redis
rb = Client(host='localhost', port=6379)
# 创建一个布隆过滤器
rb.bfCreate('myfilter', 0.01, 1000000)
# 添加一些元素
rb.bfAdd('myfilter', 'element1')
rb.bfAdd('myfilter', 'element2')
# 检查元素是否存在
print(rb.bfExists('myfilter', 'element1')) # True
print(rb.bfExists('myfilter', 'element3')) # False
幕后魔法
那么,这如何帮助减少数据库查询呢?让我们来分解一下:
- 在查询数据库之前,先检查布隆过滤器
- 如果过滤器显示元素不存在,则完全跳过数据库查询
- 如果过滤器显示可能存在,则继续进行数据库查询
这个简单的检查可以显著减少不必要的查询,特别是对于大量数据集和大量未命中的情况。
实际案例:用户认证
假设你正在构建一个用户认证系统。与其在每次使用不存在的用户名登录时都查询数据库,不如使用布隆过滤器快速拒绝无效用户名:
def authenticate_user(username, password):
if not rb.bfExists('users', username):
return "用户不存在"
# 只有在用户名可能存在时才查询数据库
user = db.get_user(username)
if user and user.check_password(password):
return "认证成功"
else:
return "无效的凭证"
注意事项和考虑
在你疯狂使用布隆过滤器之前,请记住以下几点:
- 可能出现假阳性,因此你的代码应能优雅地处理数据库未命中
- 过滤器的大小是固定的,因此要准确估计你的数据大小
- 添加元素是单向的;你不能从布隆过滤器中移除项目
性能提升:给我看数据!
让我们来看看实际数据。在一个拥有 100 万用户和 1000 万次登录尝试(90% 的用户名不存在)的测试场景中:
- 没有布隆过滤器:1000 万次数据库查询
- 使用布隆过滤器:约 190 万次数据库查询(减少 81%!)
这不仅仅是沧海一粟;而是一场效率的海啸!
扩展考虑
随着应用程序的增长,你可能需要考虑:
- 在多个 Redis 实例之间分布式布隆过滤器
- 定期重建过滤器以保持准确性
- 监控假阳性率并调整过滤器参数
高级技术:计数布隆过滤器
想要更进一步?看看计数布隆过滤器。它们允许移除元素并提供近似计数查询。以下是一个简单的例子:
# 创建一个计数布隆过滤器
rb.cfCreate('countingfilter', 1000000)
# 添加和计数元素
rb.cfAdd('countingfilter', 'element1')
rb.cfAdd('countingfilter', 'element1')
rb.cfCount('countingfilter', 'element1') # 返回 2
总结
在 Redis 中实现布隆过滤器就像给你的数据库配备了一副 X 光眼镜。它能透过噪音,专注于真正重要的东西。通过减少不必要的查询,你不仅节省了处理能力,还为用户创造了更流畅、更快速的体验。
记住,在高性能应用程序的世界中,每毫秒都很重要。所以,为什么不给你的数据库一个休息的机会,让 Redis 布隆过滤器承担一些繁重的工作呢?
思考的食粮
"编程的艺术是组织复杂性的艺术。" - Edsger W. Dijkstra
有时候,组织复杂性意味着知道什么时候不做某事。在这种情况下,就是不必要地访问数据库。
现在,去负责任地使用布隆过滤器吧!