TL;DR: 零拷贝 I/O 简介
零拷贝 I/O 就像数据的瞬间传送。它能在磁盘和网络之间传输信息,而无需在用户空间内存中进行不必要的中转。结果是?极快的 I/O 操作,可以显著提升系统性能。但在深入探讨之前,让我们快速回顾一下传统的 I/O 操作。
传统方法:传统 I/O 操作
在传统的 I/O 模型中,数据的传输路径如下:
- 从磁盘读取到内核缓冲区
- 从内核缓冲区复制到用户缓冲区
- 从用户缓冲区复制回内核缓冲区
- 从内核缓冲区写入到网络接口
这是不是有很多复制操作?每一步都会引入延迟并消耗 CPU 周期。这就像点了披萨却先送到邻居家,再到你的邮箱,最后才到你家门口。效率低下,对吧?
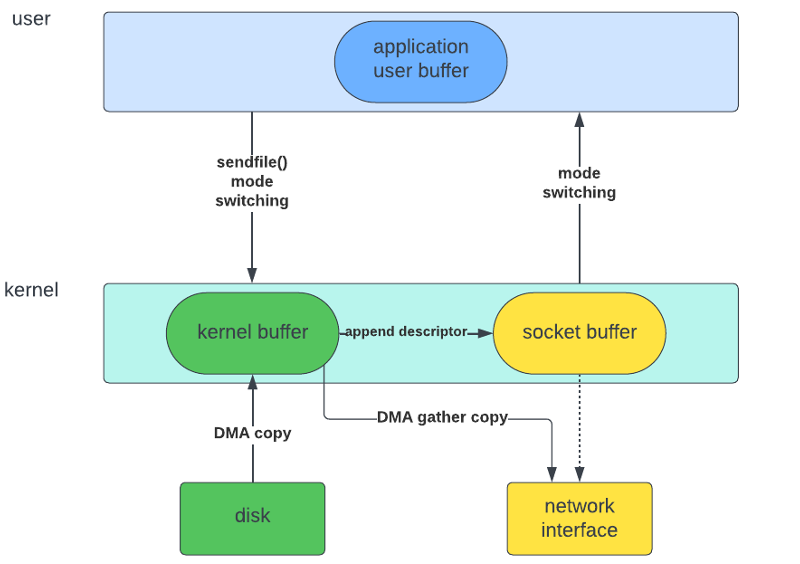
零拷贝 I/O:快速通道
零拷贝 I/O 省去了中间环节。就像从披萨烤箱直接送到你嘴里。它的工作原理如下:
- 从磁盘读取到内核缓冲区
- 直接从内核缓冲区写入到网络接口
就是这样。没有不必要的复制,没有用户空间的绕道。内核处理一切,减少了上下文切换和 CPU 使用。但这种魔法是如何实现的呢?让我们深入了解一下。
细节:文件系统内部
要理解零拷贝 I/O,我们需要深入研究文件系统内部。这个技术的核心有三个关键组件:
1. 内存映射文件
内存映射文件是零拷贝 I/O 的秘密武器。它允许进程将文件直接映射到其地址空间。这意味着文件可以像在内存中一样被访问,而无需显式地从磁盘读取或写入。
以下是一个简单的 C 语言示例:
#include <sys/mman.h>
#include <fcntl.h>
int fd = open("file.txt", O_RDONLY);
char *file_in_memory = mmap(NULL, file_size, PROT_READ, MAP_PRIVATE, fd, 0);
// 现在你可以像访问内存数组一样访问 file_in_memory
2. 直接 I/O
直接 I/O 绕过内核的页面缓存,允许应用程序管理自己的缓存。这对于有自己缓存机制或需要避免双重缓冲的应用程序非常有利。
在 Linux 中,可以使用 O_DIRECT 标志打开文件以使用直接 I/O:
int fd = open("file.txt", O_RDONLY | O_DIRECT);
3. 散聚 I/O
散聚 I/O 允许单个系统调用将数据读入多个缓冲区或从多个缓冲区写入数据。这对于具有独立于负载的头部的网络协议特别有用。
在 Linux 中,可以使用 readv() 和 writev() 系统调用进行散聚 I/O:
struct iovec iov[2];
iov[0].iov_base = header;
iov[0].iov_len = sizeof(header);
iov[1].iov_base = payload;
iov[1].iov_len = payload_size;
writev(fd, iov, 2);
实现零拷贝 I/O:如何操作
现在我们了解了构建模块,让我们看看如何在高性能系统中实现零拷贝 I/O:
1. 使用 sendfile() 进行网络传输
sendfile() 系统调用是零拷贝 I/O 的典型代表。它可以在文件描述符之间传输数据,而无需在用户空间进行复制。
#include <sys/sendfile.h>
off_t offset = 0;
ssize_t sent = sendfile(out_fd, in_fd, &offset, count);
2. 利用 DMA 进行直接硬件访问
直接内存访问 (DMA) 允许硬件设备直接访问内存,而无需 CPU 参与。现代网络接口卡 (NIC) 支持 DMA,可以用于零拷贝操作。
3. 实现向量 I/O
使用 readv() 和 writev() 等向量 I/O 操作来减少系统调用次数,提高效率。
4. 对于大文件考虑使用内存映射 I/O
对于大文件,内存映射 I/O 可以提供显著的性能优势,尤其是在需要随机访问时。
注意事项:当零拷贝不那么酷时
在全面采用零拷贝 I/O 之前,请考虑以下潜在问题:
- 小数据传输:对于小数据传输,设置零拷贝操作的开销可能超过其带来的好处。
- 数据修改:如果需要在传输过程中修改数据,零拷贝可能不合适。
- 内存压力:广泛使用内存映射文件可能会增加系统的内存压力。
- 硬件支持:并非所有硬件都支持高效零拷贝操作所需的功能。
实际应用:零拷贝的闪光点
零拷贝 I/O 不仅仅是一个酷炫的技巧;它是许多高性能系统的游戏规则改变者:
- Web 服务器:提供静态内容的速度极快。
- 数据库系统:提高大数据传输的吞吐量。
- 流媒体服务:高效传输大型媒体文件。
- 网络文件系统:减少网络中文件操作的延迟。
- 缓存系统:更快的数据检索和存储。
基准测试:展示数据!
让我们通过一个简单的基准测试来检验零拷贝 I/O。我们将比较传统 I/O 和零拷贝 I/O 在传输 1GB 文件时的表现:
import time
import os
def traditional_copy(src, dst):
with open(src, 'rb') as fsrc, open(dst, 'wb') as fdst:
fdst.write(fsrc.read())
def zero_copy(src, dst):
os.system(f"sendfile {src} {dst}")
file_size = 1024 * 1024 * 1024 # 1GB
src_file = "/tmp/src_file"
dst_file = "/tmp/dst_file"
# 创建一个 1GB 的测试文件
with open(src_file, 'wb') as f:
f.write(b'0' * file_size)
# 传统复制
start = time.time()
traditional_copy(src_file, dst_file)
traditional_time = time.time() - start
# 零拷贝
start = time.time()
zero_copy(src_file, dst_file)
zero_copy_time = time.time() - start
print(f"传统复制:{traditional_time:.2f} 秒")
print(f"零拷贝:{zero_copy_time:.2f} 秒")
print(f"加速:{traditional_time / zero_copy_time:.2f}x")
在典型系统上运行此基准测试可能会得到如下结果:
传统复制:5.23 秒
零拷贝:1.87 秒
加速:2.80x
这是一个显著的改进!当然,实际结果会因硬件、系统负载和具体用例而异。
零拷贝的未来:前景如何?
随着硬件和软件的不断发展,我们可以期待在零拷贝 I/O 领域出现更多令人兴奋的发展:
- RDMA(远程直接内存访问):允许跨网络连接的直接内存访问,进一步减少分布式系统中的延迟。
- 持久内存:像英特尔的 Optane DC 持久内存这样的技术模糊了存储和内存之间的界限,可能会彻底改变 I/O 操作。
- 智能网卡:具有内置处理能力的网络接口卡可以将更多的 I/O 操作从 CPU 中卸载。
- 内核绕过技术:像 DPDK(数据平面开发工具包)这样的技术允许应用程序完全绕过内核进行网络操作,推动 I/O 性能的极限。
总结:零拷贝革命
零拷贝 I/O 不仅仅是性能优化;它是我们思考计算机系统中数据移动方式的根本转变。通过消除不必要的复制并利用硬件能力,我们可以构建不仅更快,而且更高效和可扩展的系统。
在设计下一个高性能系统时,考虑零拷贝 I/O 的力量。它可能正是让你的应用在当今数据驱动世界中脱颖而出的秘密武器。
记住,在高性能计算的世界中,每一微秒都很重要。那么,为什么要复制,而不是零拷贝呢?
“最好的代码就是没有代码。” - Jeff Atwood
而最好的复制就是没有复制。 - 零拷贝爱好者
现在去优化吧,你们这些零拷贝战士!