我们将构建一个后端系统,将大型语言模型(LLM)的强大功能与向量数据库的精确性结合在一起,使用LangChain。结果呢?一个能够理解上下文、检索相关信息并即时生成类人响应的API。这不仅仅是智能,它是令人惊叹的智能。
RAG革命:为什么你应该关心?
在我们动手编写代码之前,让我们先来看看为什么RAG在AI世界中引起了如此大的轰动:
- 上下文为王:RAG系统比传统的基于关键词的搜索更好地理解和利用上下文。
- 新鲜且相关:与静态LLM不同,RAG可以访问和使用最新的信息。
- 减少幻觉:通过在检索到的数据中扎根,RAG有助于减少那些讨厌的AI幻觉。
- 可扩展性:随着数据的增长,AI的知识也会增长,而无需不断重新训练。
技术栈:我们的选择武器
我们不是空手上阵。以下是我们的武器库:
- LangChain:我们用于LLM操作的瑞士军刀(哦,我承诺不再用这个短语,对吧?)
- 向量数据库:我们将使用Pinecone,但你可以选择你喜欢的
- LLM:OpenAI的GPT-3.5或GPT-4(或任何你喜欢的LLM)
- FastAPI:用于构建我们快速的API端点
- Python:因为,嗯,这是Python
设置环境
首先,让我们准备好我们的环境。打开终端,安装必要的软件包:
pip install langchain pinecone-client openai fastapi uvicorn
现在,让我们创建一个基本的FastAPI应用结构:
from fastapi import FastAPI
from langchain import OpenAI, VectorDBQA
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
import pinecone
import os
app = FastAPI()
# 初始化Pinecone
pinecone.init(api_key=os.getenv("PINECONE_API_KEY"), environment=os.getenv("PINECONE_ENV"))
# 初始化OpenAI
llm = OpenAI(temperature=0.7)
# 初始化嵌入
embeddings = OpenAIEmbeddings()
# 初始化Pinecone向量存储
index_name = "your-pinecone-index-name"
vectorstore = Pinecone.from_existing_index(index_name, embeddings)
# 初始化QA链
qa = VectorDBQA.from_chain_type(llm=llm, chain_type="stuff", vectorstore=vectorstore)
@app.get("/")
async def root():
return {"message": "欢迎来到RAG驱动的API!"}
@app.get("/query")
async def query(q: str):
result = qa.run(q)
return {"result": result}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
解析:这里发生了什么?
让我们像在高中生物课上解剖青蛙一样解析这段代码(但更令人兴奋):
- 我们将FastAPI设置为我们的Web框架。
- LangChain的
OpenAI类是我们访问LLM的入口。 VectorDBQA是将我们的向量数据库与LLM结合用于问答的魔法棒。- 我们使用Pinecone作为我们的向量数据库,但你可以替换为Weaviate或Milvus等替代品。
/query端点是RAG魔法发生的地方。它接收一个问题,通过我们的QA链运行,并返回结果。
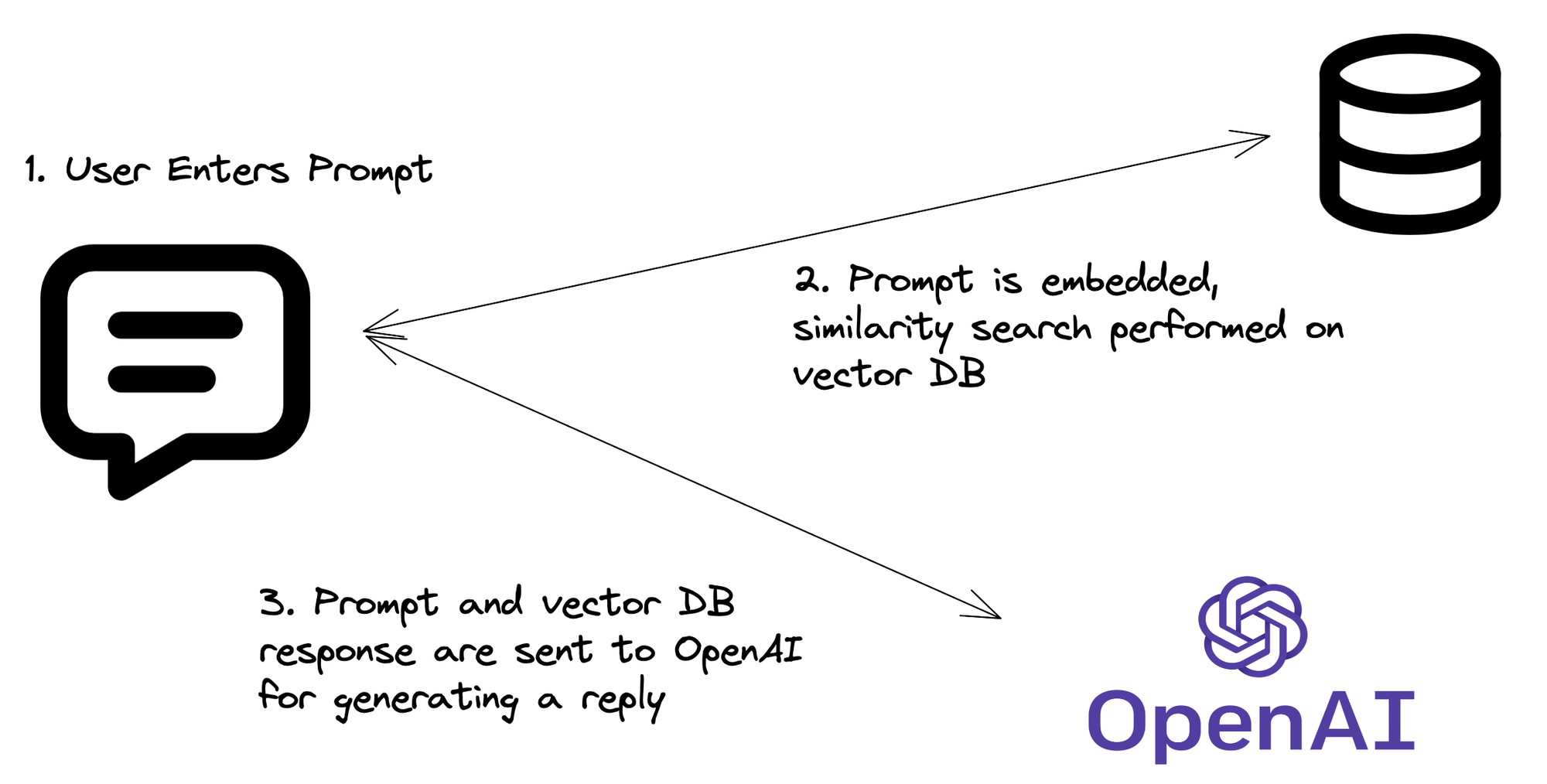
RAG流程:它实际上是如何工作的
现在我们有了代码,让我们分解RAG过程:
- 查询嵌入:你的API接收到一个问题,然后将其转换为向量嵌入。
- 向量搜索:使用此嵌入在Pinecone索引中搜索相似的向量(即相关信息)。
- 上下文检索:从Pinecone中检索最相关的文档或片段。
- LLM魔法:将原始问题和检索到的上下文发送到LLM。
- 响应生成:LLM根据问题和检索到的上下文生成响应。
- API返回:你的API返回这个智能的、上下文感知的响应。
增强你的RAG:高级技术
准备好将你的RAG系统从“相当酷”提升到“哇,太惊人了”吗?试试这些高级技术:
1. 混合搜索
结合向量搜索和传统关键词搜索以获得更好的结果:
from langchain.retrievers import PineconeHybridSearchRetriever
hybrid_retriever = PineconeHybridSearchRetriever(
embeddings=embeddings,
index=vectorstore.pinecone_index
)
qa = VectorDBQA.from_chain_type(llm=llm, chain_type="stuff", retriever=hybrid_retriever)
2. 重新排序
实施重新排序步骤以微调检索到的文档:
from langchain.retrievers import RePhraseQueryRetriever
rephraser = RePhraseQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm
)
qa = VectorDBQA.from_chain_type(llm=llm, chain_type="stuff", retriever=rephraser)
3. 流式响应
为了更具互动性,流式传输你的API响应:
from fastapi import FastAPI, Response
from fastapi.responses import StreamingResponse
@app.get("/stream")
async def stream_query(q: str):
async def event_generator():
for token in qa.run(q):
yield f"data: {token}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
潜在陷阱:小心行事!
尽管RAG很棒,但它并非没有缺陷。以下是一些需要注意的事项:
- 上下文窗口限制:LLM有最大上下文大小。确保检索到的文档不超过此限制。
- 相关性与多样性:平衡相关结果与多样信息可能很棘手。尝试调整你的检索参数。
- 幻觉尚未消失:虽然RAG减少了幻觉,但并未消除它们。始终实施安全措施和事实核查机制。
- API成本:记住,每个查询可能涉及多个API调用(嵌入、向量搜索、LLM)。注意这些费用!
总结:为什么这很重要
在你的后端实现RAG不仅仅是为了走在技术前沿(尽管这也是一个不错的奖励)。它是为了创建更智能、上下文感知的应用程序,能够以以前不可能的方式理解和响应用户查询。
通过将LLM的广泛知识与向量数据库中的特定、最新信息结合起来,你正在创建一个大于其各部分总和的系统。这就像给你的API赋予了一种超能力——能够基于实时数据理解、推理和生成类人响应。
“未来已经到来——只是分布不均。” - 威廉·吉布森
好吧,现在你是那些拥有未来一部分的幸运儿之一。去创造惊人的东西吧!
思考的食粮
在你的项目中实现RAG时,考虑以下问题:
- 你如何确保RAG系统中使用的数据的隐私和安全?
- 在部署AI驱动的API时,会涉及哪些伦理考虑?
- 随着LLM和向量数据库的不断进步,RAG系统可能会如何演变?
这些问题的答案将塑造AI驱动应用程序的未来。而现在,你正站在这场革命的前沿。编码愉快!