总结
在Kafka中实现幂等消费者对于确保数据一致性和防止重复处理至关重要。我们将探讨最佳实践、常见陷阱以及一些巧妙的技巧,以使您的Kafka消费者像数学函数一样幂等。
为什么幂等性很重要
在深入细节之前,让我们快速回顾一下为什么我们要关注幂等性:
- 防止消息的重复处理
- 确保系统中的数据一致性
- 避免深夜调试和令人抓狂的挫败感
- 增强系统对故障和重试的弹性
现在我们都在同一频道上了,让我们深入探讨精彩内容吧!
实现幂等消费者的最佳实践
1. 使用唯一的消息标识符
幂等消费者俱乐部的第一条规则是:始终使用唯一的消息标识符。(第二条规则是……你明白的。)
实现这一点很简单:
public class KafkaMessage {
private String id;
private String payload;
// ... 其他字段和方法
}
public class IdempotentConsumer {
private Set processedMessageIds = new HashSet<>();
public void consume(KafkaMessage message) {
if (processedMessageIds.add(message.getId())) {
// 处理消息
processMessage(message);
} else {
// 消息已处理,跳过
log.info("跳过重复消息: {}", message.getId());
}
}
}
专业提示:使用UUID或主题、分区和偏移量的组合作为消息ID。这就像给每条消息一个独特的雪花图案!
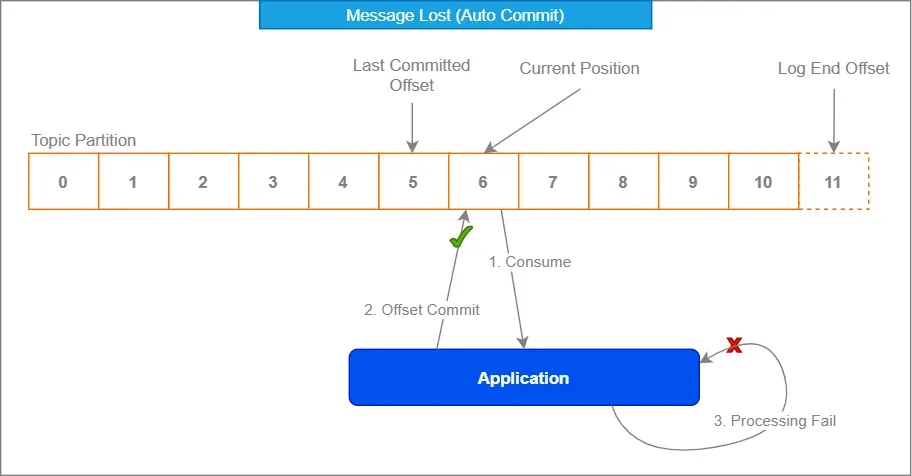
2. 利用Kafka的偏移量管理
Kafka内置的偏移量管理是您的朋友。像对待家庭聚会中那个奇怪的叔叔一样拥抱它——一开始可能显得尴尬,但它会支持你。
Properties props = new Properties();
props.put("enable.auto.commit", "false");
props.put("isolation.level", "read_committed");
KafkaConsumer consumer = new KafkaConsumer<>(props);
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord record : records) {
processRecord(record);
}
consumer.commitSync();
}
通过禁用自动提交并在处理后手动提交偏移量,您可以确保只有在100%确认消息已正确处理后才将其标记为已消费。
3. 实施去重策略
有时,尽管我们尽了最大努力,重复项还是会像偷偷摸摸的忍者一样溜进来。这时,一个可靠的去重策略就派上用场了。
考虑使用像Redis这样的分布式缓存来存储已处理的消息ID:
@Service
public class DuplicateChecker {
private final RedisTemplate redisTemplate;
public DuplicateChecker(RedisTemplate redisTemplate) {
this.redisTemplate = redisTemplate;
}
public boolean isDuplicate(String messageId) {
return !redisTemplate.opsForValue().setIfAbsent(messageId, "processed", Duration.ofDays(1));
}
}
这种方法允许您在多个消费者实例之间甚至在重启后检查重复项。就像为您的消息设置了一个保镖——“如果您的ID不在名单上,您就进不去!”
4. 使用幂等操作
尽可能设计您的消息处理操作为自然幂等。这意味着即使多次处理消息,也不会影响最终结果。
例如,代替:
public void incrementCounter(String counterId) {
int currentValue = counterRepository.get(counterId);
counterRepository.set(counterId, currentValue + 1);
}
考虑使用原子操作:
public void incrementCounter(String counterId) {
counterRepository.increment(counterId);
}
这样,即使对同一消息多次调用增量操作,最终结果也将保持不变。
常见陷阱及其避免方法
现在我们已经涵盖了基础知识,让我们来看看一些即使是经验丰富的开发人员也可能会陷入的常见陷阱:
1. 仅依赖Kafka的“精确一次”语义
虽然Kafka提供“精确一次”语义,但这不是万能的。它只保证在Kafka集群内的精确一次交付,而不是在您的应用程序中的端到端精确一次处理。
“信任,但要验证”——罗纳德·里根(可能是在谈论Kafka消息)
除了Kafka的保证外,始终实现您自己的幂等性检查。
2. 忽略事务边界
确保您的消息处理和偏移量提交是同一事务的一部分。否则,您可能会遇到处理了消息但未提交偏移量的情况,导致消费者重启时重新处理。
@Transactional
public void processMessage(ConsumerRecord record) {
// 处理消息
businessLogic.process(record.value());
// 手动确认消息
acknowledgment.acknowledge();
}
3. 忽视数据库约束
如果您将处理的数据存储在数据库中,请利用唯一约束。它们可以作为防止重复的额外保护层。
CREATE TABLE processed_messages (
message_id VARCHAR(255) PRIMARY KEY,
processed_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
然后,在您的Java代码中:
try {
jdbcTemplate.update("INSERT INTO processed_messages (message_id) VALUES (?)", messageId);
// 处理消息
} catch (DuplicateKeyException e) {
// 消息已处理,跳过
}
勇敢者的高级技巧
准备好将您的幂等消费者技能提升到一个新的水平了吗?以下是一些适合勇敢者的高级技巧:
1. 在头部使用幂等键
与其依赖消息内容来实现幂等性,不如考虑使用Kafka消息头来存储幂等键。这允许在保持幂等性的同时拥有更灵活的消息内容。
// 生产者
ProducerRecord record = new ProducerRecord<>("my-topic", "key", "value");
record.headers().add("idempotency-key", UUID.randomUUID().toString().getBytes());
producer.send(record);
// 消费者
ConsumerRecord record = // ... 从Kafka接收
byte[] idempotencyKeyBytes = record.headers().lastHeader("idempotency-key").value();
String idempotencyKey = new String(idempotencyKeyBytes, StandardCharsets.UTF_8);
2. 基于时间的去重
在某些情况下,您可能希望实现基于时间的去重。这在处理事件流时很有用,因为在某段时间后,同一事件可能会合法地重复。
public class TimeBasedDuplicateChecker {
private final RedisTemplate redisTemplate;
private final Duration deduplicationWindow;
public TimeBasedDuplicateChecker(RedisTemplate redisTemplate, Duration deduplicationWindow) {
this.redisTemplate = redisTemplate;
this.deduplicationWindow = deduplicationWindow;
}
public boolean isDuplicate(String messageId) {
String key = "dedup:" + messageId;
Boolean isNew = redisTemplate.opsForValue().setIfAbsent(key, "processed", deduplicationWindow);
return isNew != null && !isNew;
}
}
3. 幂等聚合
在处理聚合操作时,考虑使用幂等聚合技术。例如,与其存储运行总和,不如存储单个值并即时计算总和:
public class IdempotentAggregator {
private final Map values = new ConcurrentHashMap<>();
public void addValue(String key, double value) {
values.put(key, value);
}
public double getSum() {
return values.values().stream().mapToDouble(Double::doubleValue).sum();
}
}
这种方法确保即使多次处理消息,也不会影响最终的聚合结果。
总结
在Kafka中实现幂等消费者可能看起来是一项艰巨的任务,但通过这些最佳实践和技术,您将很快像专业人士一样处理重复项。记住,关键是始终预料到意外,并从一开始就以幂等性为设计目标。
这里有一个快速检查清单供您参考:
- 使用唯一的消息标识符
- 利用Kafka的偏移量管理
- 实施强大的去重策略
- 尽可能设计自然幂等的操作
- 了解常见陷阱及其避免方法
- 针对特定用例考虑高级技术
通过遵循这些指导原则,您不仅可以提高基于Kafka的系统的可靠性和一致性,还可以为自己节省无数的调试时间和头痛。说实话,这不就是我们所追求的吗?
现在去征服那些重复的消息吧!您的未来自我(以及您的运维团队)会感谢您。
“在Kafka消费者的世界中,幂等性不仅仅是一个特性——它是一种超能力。”——某位聪明的开发者(可能)
祝编码愉快,愿您的消费者始终保持幂等!