总结:幂等性是你的新好朋友
幂等性确保操作在重复执行时,不会改变系统的状态,超出初始应用的范围。这对于维护分布式系统的一致性至关重要,尤其是在处理网络问题、重试和并发请求时。我们将讨论:
- 幂等的REST API:因为一个订单总比五个相同的订单好
- Kafka消费者幂等性:确保你的消息只被处理一次
- 分布式任务队列:确保你的工作者们和谐共处
幂等的REST API:一个订单统领全局
让我们从REST API开始,这是现代后端系统的基础。在这里实现幂等性至关重要,特别是对于修改状态的操作。
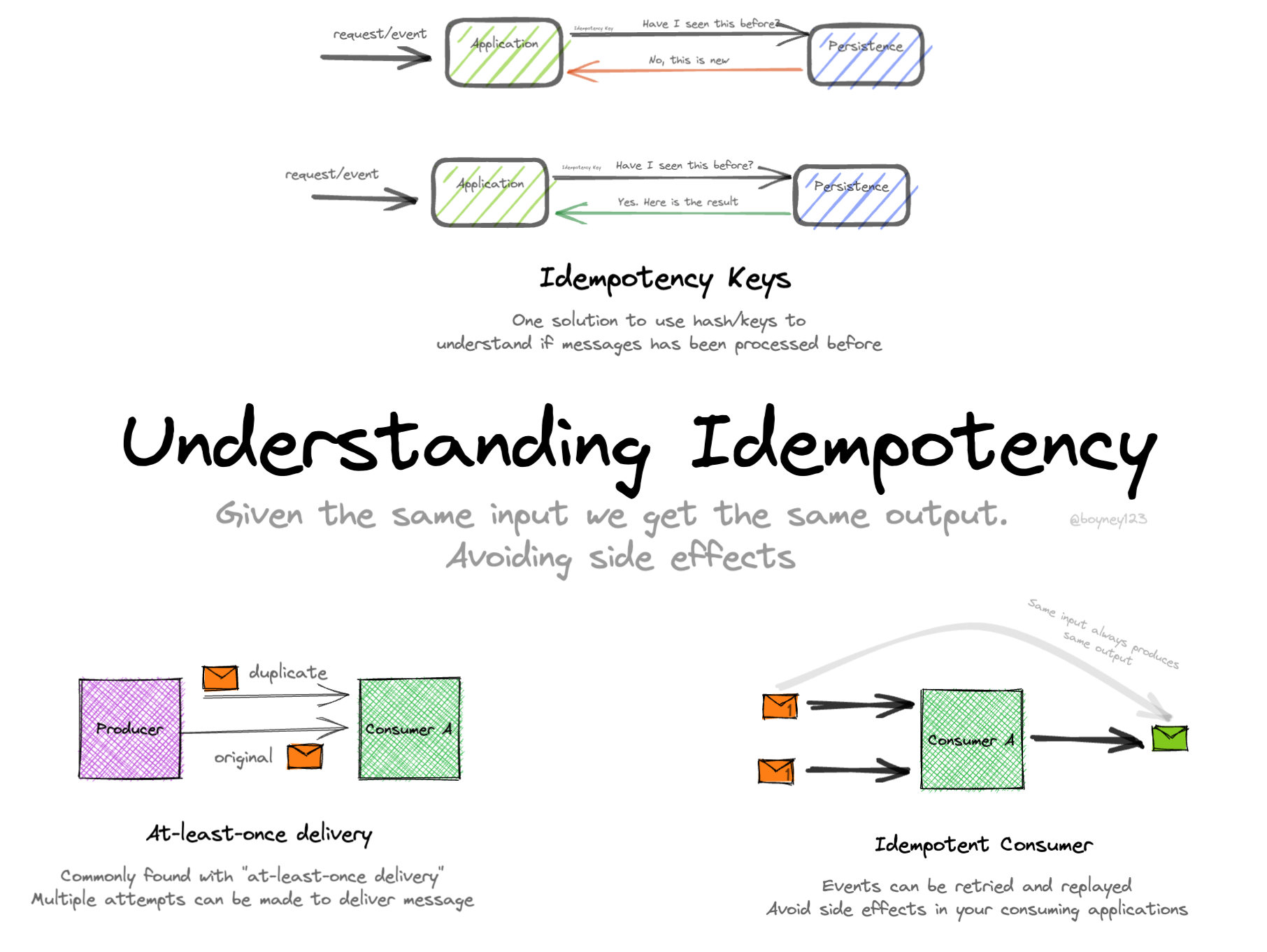
幂等键模式
一种有效的技术是使用幂等键。其工作原理如下:
- 客户端为每个请求生成一个唯一的幂等键。
- 服务器将此键与第一次成功请求的响应一起存储。
- 对于具有相同键的后续请求,服务器返回存储的响应。
以下是使用Flask的Python快速示例:
from flask import Flask, request, jsonify
import redis
app = Flask(__name__)
redis_client = redis.Redis(host='localhost', port=6379, db=0)
@app.route('/api/order', methods=['POST'])
def create_order():
idempotency_key = request.headers.get('Idempotency-Key')
if not idempotency_key:
return jsonify({"error": "Idempotency-Key header is required"}), 400
# 检查我们是否见过这个键
cached_response = redis_client.get(idempotency_key)
if cached_response:
return jsonify(eval(cached_response)), 200
# 处理订单
order = process_order(request.json)
# 存储响应
redis_client.set(idempotency_key, str(order), ex=3600) # 1小时后过期
return jsonify(order), 201
def process_order(order_data):
# 你的订单处理逻辑
return {"order_id": "12345", "status": "created"}
if __name__ == '__main__':
app.run(debug=True)
注意:键生成和过期
虽然幂等键模式很强大,但它也有自己的挑战:
- 键生成:确保客户端生成真正唯一的键。UUID4是一个不错的选择,但要记住处理潜在的(尽管很少见)冲突。
- 键过期:不要永远保留这些键!根据系统的需要设置适当的TTL。
- 存储可扩展性:随着系统的增长,键存储也会增长。在基础设施中为此做好计划。
"拥有强大的幂等性意味着承担巨大的责任……以及大量的键管理。"
Kafka消费者幂等性:驯服数据流
啊,Kafka!这个分布式流平台要么是你的好朋友,要么是你的噩梦,这取决于你如何处理幂等性。
“精确一次”语义
Kafka 0.11.0引入了“精确一次”语义的概念,这对幂等消费者来说是一个游戏规则的改变。以下是如何利用它:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("enable.idempotence", true);
props.put("acks", "all");
props.put("retries", Integer.MAX_VALUE);
props.put("max.in.flight.requests.per.connection", 5);
Producer producer = new KafkaProducer<>(props);
但等等,还有更多!要真正实现幂等性,你还需要考虑你的消费者逻辑:
@KafkaListener(topics = "orders")
public void listen(ConsumerRecord record) {
String orderId = record.key();
String orderDetails = record.value();
// 检查我们是否处理过这个订单
if (orderRepository.existsById(orderId)) {
log.info("Order {} already processed, skipping", orderId);
return;
}
// 处理订单
Order order = processOrder(orderDetails);
orderRepository.save(order);
}
注意:去重难题
虽然Kafka的精确一次语义很强大,但它不是万能的:
- 去重窗口:你会跟踪处理过的消息多久?太短会有重复,太长会导致存储爆炸。
- 排序保证:确保你的去重不会破坏消息排序语义,尤其是在重要的地方。
- 有状态处理:对于复杂的有状态操作,考虑使用Kafka Streams及其内置状态存储,以实现更强大的幂等性。
分布式任务队列:当工作者需要和谐共处
像Celery或Bull这样的分布式任务队列非常适合卸载工作,但如果不以幂等方式处理,它们可能会成为噩梦。让我们看看一些策略,以确保你的工作者们和谐共处。
“检查然后行动”模式
这种模式涉及在执行任务之前检查任务是否已完成。以下是使用Celery的示例:
from celery import Celery
from myapp.models import Order
app = Celery('tasks', broker='redis://localhost:6379')
@app.task(bind=True, max_retries=3)
def process_order(self, order_id):
try:
order = Order.objects.get(id=order_id)
# 检查订单是否已处理
if order.status == 'processed':
return f"Order {order_id} already processed"
# 处理订单
result = do_order_processing(order)
order.status = 'processed'
order.save()
return result
except Exception as exc:
self.retry(exc=exc, countdown=60) # 1分钟后重试
def do_order_processing(order):
# 你的实际订单处理逻辑
pass
注意:竞争条件和部分失败
“检查然后行动”模式并非没有挑战:
- 竞争条件:在高并发场景中,多个工作者可能同时通过检查。考虑使用数据库锁或分布式锁(例如基于Redis的)来处理关键部分。
- 部分失败:如果任务在中途失败怎么办?设计你的任务,要么完全完成,要么完全可回滚。
- 幂等性令牌:对于更复杂的场景,考虑实现类似于我们之前讨论的REST API模式的幂等性令牌系统。
哲学角:为什么要费这么大劲?
你可能会想,“为什么要费这么大劲?我们不能就这样随便做,然后希望一切顺利吗?”好吧,我的朋友,在分布式系统的世界里,希望不是一种策略。幂等性至关重要,因为:
- 它确保系统中的数据一致性。
- 它使系统更能抵御网络问题和重试。
- 它简化了错误处理和调试。
- 它使分布式架构的扩展和维护更容易。
"在分布式系统中,幂等性不仅仅是一个可有可无的功能;它是一个系统能够优雅地处理故障与迅速陷入混乱之间的区别,比你说‘网络分区’还快。"
总结:你的幂等性工具包
正如我们所见,在分布式后端系统中实现幂等性并非易事,但对于构建强大、可扩展的应用程序来说绝对至关重要。以下是你的幂等性工具包:
- 对于REST API:使用幂等键和谨慎的请求处理。
- 对于Kafka消费者:利用“精确一次”语义并实施智能去重。
- 对于分布式任务队列:采用“检查然后行动”模式,并注意竞争条件。
记住,幂等性不仅仅是一个功能;它是一种思维方式。从系统设计阶段开始考虑它,当你的服务在网络故障、服务重启和那些可怕的凌晨3点生产问题面前依然顺利运行时,你会感谢自己。
现在去吧,让你的分布式系统变得幂等!你的未来自我(以及你的运维团队)会感谢你。
进一步阅读
编码愉快,愿你的系统始终保持一致!