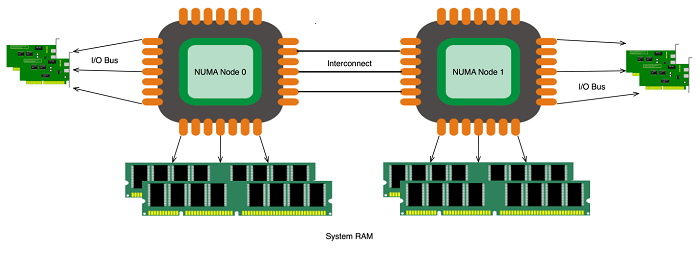
NUMA 的难题
在我们深入探讨调度器调优之前,先来了解一下背景。非统一内存访问(NUMA)架构已经成为现代服务器硬件的标准。然而,问题在于:我们中的许多人仍然在开发和部署 Go 微服务时,像是在使用统一内存访问。这就像试图将方钉塞入圆孔——虽然可能勉强可行,但远非最佳选择。
为什么 NUMA 对 Go 微服务很重要
Go 的运行时相当智能,但它并非无所不知。在 NUMA 感知方面,它需要我们这些普通人的一点帮助。以下是 NUMA 感知对您的 Go 微服务至关重要的原因:
- 本地和远程 NUMA 节点之间的内存访问延迟可能会显著不同
- 不当的线程和内存分配可能导致性能下降
- Go 的垃圾回收器性能可能受到 NUMA 效应的影响
在您的 Go 微服务中忽视 NUMA 就像在计划公路旅行时忽视交通的存在。当然,您可能会到达目的地,但旅程将远非顺利。
引入完全公平调度器(CFS)
现在,让我们来谈谈我们的主角:完全公平调度器。尽管名字如此,CFS 在 NUMA 系统中并不总是完全公平。但通过一些调优,我们可以让它为我们的 Go 微服务发挥奇效。
CFS:优点、缺点和 NUMA 的丑陋
CFS 的设计初衷是公平。它试图为每个进程提供相等的 CPU 时间。但在 NUMA 世界中,公平并不总是我们想要的。有时,为了实现最佳性能,我们需要有点不公平。以下是快速概述:
- 优点: CFS 提供良好的整体系统响应性和公平性
- 缺点: 它可能导致 NUMA 节点之间不必要的任务迁移
- NUMA 的丑陋: 如果没有适当的调优,它可能导致 Go 微服务的内存访问延迟增加
为 NUMA 感知的 Go 微服务调优 CFS
好了,是时候卷起袖子,动手进行一些调度器调优了。以下是我们将重点关注的关键领域:
1. 调整调度域
调度域定义了调度器如何查看系统拓扑。通过调整这些,我们可以使 CFS 更加 NUMA 感知:
# 查看当前调度域
cat /proc/sys/kernel/sched_domain/cpu0/domain*/name
# 调整调度域参数
echo 1 > /proc/sys/kernel/sched_domain/cpu0/domain0/prefer_local_spreading
这告诉调度器在可能的情况下,优先将任务保持在同一个 NUMA 节点上,减少不必要的迁移。
2. 微调 sched_migration_cost_ns
此参数控制调度器在 CPU 之间迁移任务的积极程度。对于运行 Go 微服务的 NUMA 系统,我们通常希望增加此值:
# 查看当前值
cat /proc/sys/kernel/sched_migration_cost_ns
# 增加值(例如,增加到 1000000 纳秒)
echo 1000000 > /proc/sys/kernel/sched_migration_cost_ns
此更改使调度器不太可能在 NUMA 节点之间移动任务,从而减少远程内存访问的机会。
3. 利用 cgroups 进行 NUMA 感知的资源分配
控制组(cgroups)可以是强制执行 NUMA 感知资源分配的强大工具。以下是如何使用 cgroups 将 Go 微服务固定到特定 NUMA 节点的简单示例:
# 为我们的 Go 微服务创建一个 cgroup
mkdir /sys/fs/cgroup/cpuset/go_microservice
# 分配 CPU 和内存节点
echo "0-3" > /sys/fs/cgroup/cpuset/go_microservice/cpuset.cpus
echo "0" > /sys/fs/cgroup/cpuset/go_microservice/cpuset.mems
# 在此 cgroup 中运行 Go 微服务
cgexec -g cpuset:go_microservice ./my_go_microservice
这确保我们的 Go 微服务仅使用来自单个 NUMA 节点的 CPU 和内存,减少跨节点内存访问。
Go 运行时:您的 NUMA 感知盟友
虽然我们专注于调度器调优,但不要忘记 Go 的运行时可以成为我们追求 NUMA 感知的盟友。以下是一些 Go 特定的提示:
1. GOGC 和 NUMA
GOGC 环境变量控制 Go 的垃圾回收器行为。在 NUMA 系统中,您可能希望调整此值以减少全局回收的频率:
export GOGC=200
这告诉 Go 运行时减少垃圾回收的频率,可能在回收期间减少跨节点内存访问。
2. 利用 runtime.NumCPU()
在为 NUMA 系统编写 Go 代码时,请注意您如何使用 goroutine。以下是如何创建 NUMA 感知工作池的简单示例:
import "runtime"
func createNUMAAwareWorkerPool() {
numCPU := runtime.NumCPU()
for i := 0; i < numCPU; i++ {
go worker(i)
}
}
func worker(id int) {
runtime.LockOSThread()
// 工作逻辑在这里
}
通过使用 runtime.NumCPU() 和 runtime.LockOSThread(),我们创建了一个更可能尊重 NUMA 边界的工作池。
衡量影响
所有这些调优都很好,但我们如何知道它是否真的产生了影响?以下是一些需要关注的工具和指标:
- numastat: 提供 NUMA 内存统计信息
- perf: 可用于测量缓存未命中和内存访问模式
- Go 的内置分析: 使用
runtime/pprof在调优前后分析您的应用程序
以下是如何使用 numastat 检查 NUMA 内存使用情况的快速示例:
numastat -p $(pgrep my_go_microservice)
查找 NUMA 节点之间内存分配的不平衡。如果您看到大量“外来”内存访问,您的调优可能需要一些调整。
陷阱和注意事项
在您开始调优每个系统之前,先说一句警告:
- 过度调优可能导致资源未充分利用
- 对一个 Go 微服务有效的方法可能对另一个无效
- 调度器调优可能与 Go 的运行时行为复杂交互
始终在受控环境中测量、测试和验证您的更改,然后再推送到生产环境。记住,能力越大,责任越大(如果不小心,可能会带来巨大的头痛)。
总结:平衡的艺术
为 NUMA 感知的 Go 微服务调优完全公平调度器确实是一门艺术。它是关于在公平性、性能和资源利用之间找到正确的平衡。以下是关键要点:
- 了解您的硬件:NUMA 架构很重要
- 以 NUMA 为中心调优 CFS 参数
- 利用 cgroups 进行精细控制
- 与 Go 的运行时合作,而不是对抗它
- 始终测量和验证您的调优工作
记住,目标不是创建一个完美的 NUMA 感知系统(这几乎是不可能的),而是找到一个甜蜜点,让您的 Go 微服务在 NUMA 架构的限制下表现最佳。
所以,下次有人说,“这只是一个调度器,能有多复杂?”您可以会心一笑,并指向这篇文章。祝您调优愉快,愿您的 Go 微服务在 NUMA 节点上永远顺利运行!
“在 NUMA 感知的 Go 微服务世界中,调度器不仅仅是裁判——它是代码与硬件之间复杂舞蹈的编舞者。”
您有关于 NUMA 系统调度器调优的战斗故事吗?或者一些关于 NUMA 感知的巧妙 Go 技巧?请在下面的评论中分享。让我们从彼此的成功(和灾难)中学习!