优雅降级的核心是让你的系统在不完美的情况下仍能正常运行。我们将探讨一些策略,如断路器、速率限制和优先级排序,以帮助你的后端系统应对任何挑战。准备好,这将是一段颠簸但富有教育意义的旅程!
为什么要关心优雅降级?
说实话:在理想的世界中,我们的系统会全天候无故障运行。但我们生活在现实世界中,墨菲定律总是在暗中潜伏。优雅降级是我们对墨菲定律的回应,表示“不错的尝试,但我们已经准备好了。”
这就是它的重要性:
- 在系统出现问题时保持关键功能的正常运行
- 防止级联故障导致整个系统崩溃
- 在高压力时期改善用户体验
- 为解决问题提供缓冲时间,避免全面危机
优雅降级的策略
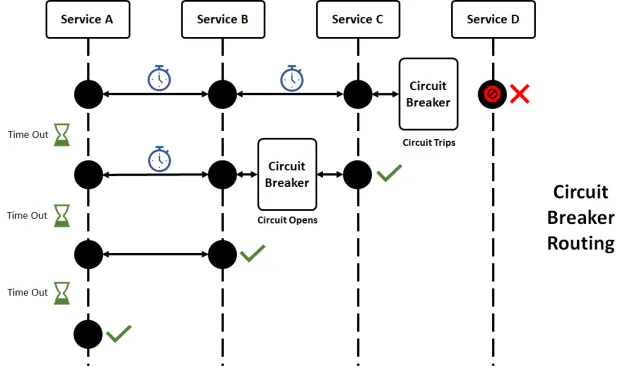
1. 断路器:系统的保险丝盒
还记得小时候插太多圣诞灯导致保险丝烧断的情景吗?软件中的断路器类似,保护你的系统不被过载。
以下是使用Hystrix库的简单实现:
public class ExampleCommand extends HystrixCommand {
private final String name;
public ExampleCommand(String name) {
super(HystrixCommandGroupKey.Factory.asKey("ExampleGroup"));
this.name = name;
}
@Override
protected String run() {
// 这可能是一个API调用或数据库查询
return "Hello " + name + "!";
}
@Override
protected String getFallback() {
return "Hello Guest!";
}
}
在这个例子中,如果run()方法失败或耗时过长,断路器会启动并调用getFallback()。这就像为你的代码准备了一个备用发电机!
2. 速率限制:教你的API一些礼貌
速率限制就像是俱乐部的保镖。你不希望太多请求同时涌入,否则可能会变得混乱。以下是使用Spring Boot和Bucket4j的实现方法:
@RestController
public class ApiController {
private final Bucket bucket;
public ApiController() {
Bandwidth limit = Bandwidth.classic(20, Refill.greedy(20, Duration.ofMinutes(1)));
this.bucket = Bucket.builder()
.addLimit(limit)
.build();
}
@GetMapping("/api/resource")
public ResponseEntity getResource() {
if (bucket.tryConsume(1)) {
return ResponseEntity.ok("Here's your resource!");
}
return ResponseEntity.status(429).body("Too many requests, please try again later.");
}
}
这个设置允许每分钟20个请求。超过这个数量,你会被礼貌地要求稍后再试。就像你的API学会了排队!
3. 优先级排序:并非所有请求都同等重要
当情况变得艰难时,你需要知道该优先处理什么。这就像急诊室的分诊——先处理关键操作,猫咪GIF稍后再看(抱歉,猫咪爱好者)。
考虑为你的请求实现一个优先级队列:
public class PriorityRequestQueue {
private PriorityQueue queue;
public PriorityRequestQueue() {
this.queue = new PriorityQueue<>((r1, r2) -> r2.getPriority() - r1.getPriority());
}
public void addRequest(Request request) {
queue.offer(request);
}
public Request processNextRequest() {
return queue.poll();
}
}
这确保了在资源有限时,高优先级请求(如支付或关键用户操作)会被优先处理。
优雅失败的艺术
现在我们已经讨论了一些策略,让我们来谈谈优雅失败的艺术。这不仅仅是为了避免彻底崩溃,而是在逆境中保持尊严。以下是一些建议:
- 清晰沟通:在服务降级时,与用户保持透明。简单的“我们正在经历高需求,一些功能可能暂时不可用”会有很大帮助。
- 渐进降级:不要从100降到0。首先禁用非关键功能,尽可能长时间保持核心功能完好。
- 智能重试:实现指数退避重试,以避免对已经压力过大的服务造成冲击。
- 缓存策略:在高峰期明智地使用缓存,以减少后端服务的负载。
监控:你的预警系统
实施优雅降级策略是很好的,但你如何知道何时触发它们?这就需要监控——你的系统预警系统。
考虑使用Prometheus和Grafana等工具来监控关键指标:
- 响应时间
- 错误率
- CPU和内存使用率
- 队列长度
设置警报,不仅在情况变糟时触发,还在它们开始看起来有点不对劲时触发。这就像为你的系统提供天气预报——你希望在风暴来临前知道。
测试你的降级策略
你不会在不测试的情况下部署代码,对吧?(对吧?!)同样适用于你的降级策略。进入混沌工程——故意破坏的艺术。
像Chaos Monkey这样的工具可以帮助你在受控环境中模拟故障和高负载场景。这就像为你的系统进行消防演习。当然,这可能有点紧张,但总比在真正的火灾中发现洒水器不起作用要好。
现实世界的例子:Netflix的方法
让我们快速看看流媒体巨头Netflix如何处理优雅降级。他们使用一种称为“按优先级回退”的技术。以下是他们方法的简化版本:
- 尝试获取用户的个性化推荐。
- 如果失败,则回退到他们所在地区的热门标题。
- 如果区域数据不可用,则显示整体热门标题。
- 作为最后的手段,显示一个静态的预定义标题列表。
这确保了用户总能看到某些内容,即使这不是理想的个性化体验。这是一个在降级功能的同时仍然提供价值的好例子。
结论:拥抱混乱
设计优雅降级不仅仅是处理故障;它是接受分布式系统的混乱本质。接受事情会出错并为此做好计划。这是从“哎呀,我们的错!”到“我们已经掌控局面”的区别。
记住:
- 实施断路器以防止级联故障
- 使用速率限制来管理高负载场景
- 在资源稀缺时优先处理关键操作
- 在降级状态下与用户清晰沟通
- 监控、测试并持续改进你的降级策略
通过遵循这些策略,你不仅是在构建一个系统;你是在构建一个经过考验的战士,准备好面对数字世界抛出的任何混乱。现在,去优雅地降级吧!
“系统的真正考验不是在一切顺利时的表现,而是在一切出错时的表现。” - 匿名DevOps哲学家
你在系统中有过关于优雅降级的战斗故事吗?在评论中分享吧!毕竟,一个开发者的噩梦是另一个人的学习机会。祝编码愉快,愿你的系统总是优雅地降级!