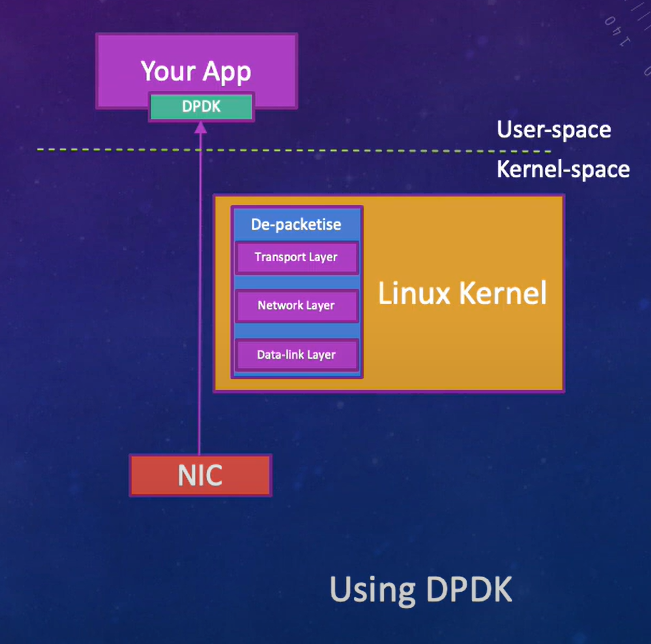
为什么绕过内核?
Linux内核的网络栈是工程学的奇迹,能够处理各种协议和用例。但对于某些高性能应用来说,它可能显得过于复杂。可以把它想象成使用瑞士军刀,而你只需要激光束。
通过将我们的TCP/IP栈移到用户空间,我们可以:
- 消除内核和用户空间之间的上下文切换
- 通过使用轮询来避免中断
- 根据我们的具体需求定制栈
- 对内存分配和数据包处理进行更细粒度的控制
DPDK:速度恶魔登场
数据平面开发工具包(DPDK)是我们在性能战中的秘密武器。它是一组用于用户空间快速数据包处理的库和驱动程序。DPDK绕过内核,直接访问网络接口卡(NIC)。
我们将使用的DPDK关键特性:
- 轮询模式驱动程序(PMD):告别中断!
- 大页:用于高效的内存管理
- NUMA感知内存分配:让数据靠近需要它的CPU
- 无锁环形缓冲区:因为锁已经过时了
Rust:光速下的安全性
你问为什么选择Rust?除了它是编程语言中的酷小子,Rust还提供:
- 零成本抽象:在不牺牲可读性的情况下提升性能
- 无垃圾回收的内存安全:没有意外的暂停
- 无畏的并发:因为我们需要尽可能多的核心
- 不断增长的网络库生态系统:站在巨人的肩膀上
蓝图:构建我们的栈
让我们将方法分解为可管理的部分:
1. 设置DPDK
首先,我们需要设置DPDK。这包括编译DPDK、配置大页以及将我们的NIC绑定到DPDK兼容的驱动程序。
# 安装依赖
sudo apt-get install -y build-essential libnuma-dev
# 克隆并编译DPDK
git clone https://github.com/DPDK/dpdk.git
cd dpdk
meson build
ninja -C build
sudo ninja -C build install
2. Rust和DPDK:天作之合
我们将使用rust-dpdk库在Rust中与DPDK进行接口。将其添加到你的Cargo.toml中:
[dependencies]
rust-dpdk = "0.2"
3. 在Rust中初始化DPDK
让我们启动并运行DPDK:
use rust_dpdk::*;
fn main() {
// 初始化EAL(环境抽象层)
let eal_args = vec![
"hello_dpdk".to_string(),
"-l".to_string(),
"0-3".to_string(),
"-n".to_string(),
"4".to_string(),
];
dpdk_init(eal_args).expect("Failed to initialize DPDK");
// 其余代码...
}
4. 实现TCP/IP栈
现在是有趣的部分!我们将实现一个简单的TCP/IP栈。以下是一个高层次的概述:
- 以太网帧处理
- IP数据包处理
- TCP段管理
- 连接状态跟踪
让我们看看一个简化的TCP头解析函数:
struct TcpHeader {
src_port: u16,
dst_port: u16,
seq_num: u32,
ack_num: u32,
// ... 其他字段
}
fn parse_tcp_header(packet: &[u8]) -> Result {
if packet.len() < 20 {
return Err(ParseError::PacketTooShort);
}
Ok(TcpHeader {
src_port: u16::from_be_bytes([packet[0], packet[1]]),
dst_port: u16::from_be_bytes([packet[2], packet[3]]),
seq_num: u32::from_be_bytes([packet[4], packet[5], packet[6], packet[7]]),
ack_num: u32::from_be_bytes([packet[8], packet[9], packet[10], packet[11]]),
// ... 解析其他字段
})
}
5. 利用无锁环形缓冲区
DPDK的环形缓冲区是实现高性能的关键组件。我们将使用它们在处理管道的不同阶段之间传递数据包:
use rust_dpdk::rte_ring::*;
// 创建一个环形缓冲区
let ring = rte_ring_create("packet_ring", 1024, SOCKET_ID_ANY, 0)
.expect("Failed to create ring");
// 入队一个数据包
let mut packet: *mut rte_mbuf = /* ... */;
rte_ring_enqueue(ring, packet as *mut c_void);
// 出队一个数据包
let mut packet: *mut rte_mbuf = std::ptr::null_mut();
rte_ring_dequeue(ring, &mut packet as *mut *mut c_void);
6. 轮询模式的魔力
我们将不断轮询新数据包,而不是等待中断:
use rust_dpdk::rte_eth_rx_burst;
fn poll_for_packets(port_id: u16, queue_id: u16) {
let mut rx_pkts: [*mut rte_mbuf; 32] = [std::ptr::null_mut(); 32];
loop {
let nb_rx = unsafe {
rte_eth_rx_burst(port_id, queue_id, rx_pkts.as_mut_ptr(), rx_pkts.len() as u16)
};
for i in 0..nb_rx {
process_packet(rx_pkts[i as usize]);
}
}
}
性能调优:对速度的需求
为了达到10M+ PPS的目标,我们需要优化栈的每个方面:
- 使用多个核心并实施适当的工作分配策略
- 通过对齐数据结构来最小化缓存未命中
- 批量处理数据包以摊销函数调用开销
- 尽可能实现零拷贝操作
- 不断分析和优化热点路径
潜在陷阱:这里有龙
在你重新编写整个网络栈之前,请考虑这些潜在问题:
- 复杂性增加:调试用户空间网络可能具有挑战性
- 协议支持有限:你可能需要从头实现协议
- 安全考虑:强大的能力伴随着巨大的责任(和潜在的漏洞)
- 可移植性:你的解决方案可能与特定硬件或DPDK版本绑定
终点线:值得吗?
经过所有这些工作,你可能会想这是否值得。答案,正如软件工程中常见的那样,是“视情况而定”。如果你正在构建一个高频交易平台、网络设备或任何纳秒级别重要的系统,那么绝对值得!你刚刚解锁了以前无法达到的性能新水平。
另一方面,如果你正在开发一个典型的Web应用程序,这可能显得过于复杂。记住,过早优化是万恶之源(或至少是那棵树上的一个重要分支)。
我们学到了什么?
让我们回顾一下我们在用户空间网络深处的旅程中的关键要点:
- 绕过内核可以为特定用例带来显著的性能提升
- DPDK为高性能数据包处理提供了强大的工具
- Rust的安全保证和零成本抽象使其成为系统编程的绝佳选择
- 实现10M+ PPS需要在栈的每个层次进行仔细优化
- 强大的能力伴随着巨大的责任——用户空间网络并不适合所有应用
思考的食粮
在我们结束时,这里有一些问题供你思考:
- 随着eBPF等技术的出现,这种方法会如何改变?
- AI/ML能否用于动态优化数据包处理路径?
- 系统编程的其他哪些领域可以从这种用户空间方法中受益?
记住,在高性能网络的世界中,唯一的限制是你的想象力(也许还有光速,但我们也在努力解决这个问题)。现在,去以疯狂的速度处理那些数据包吧!
"互联网?那东西还在吗?" - 荷马·辛普森
附言:如果你读到这里,恭喜你!你现在正式成为网络极客。带着自豪感佩戴这个徽章,愿你的数据包总能找到它们的目的地!