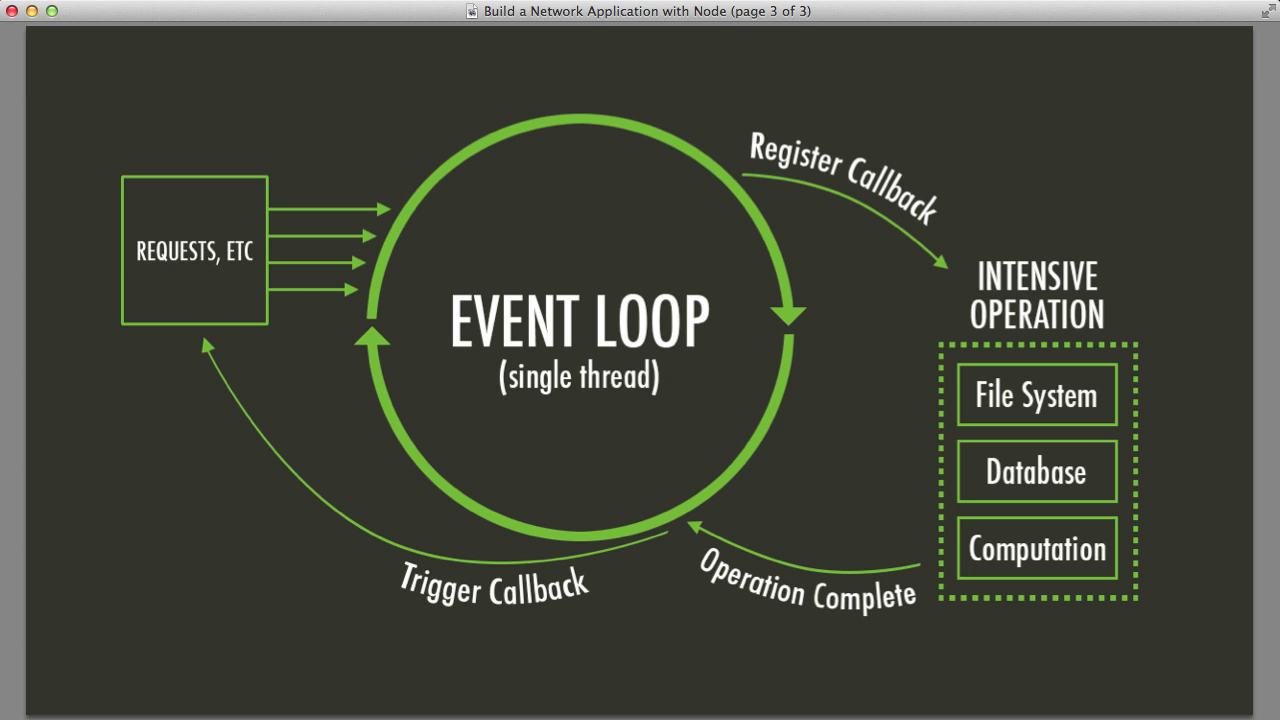
事件循环是 Node.js 的核心,就像血液在静脉中流动一样,将异步操作传递到你的应用程序中。它是单线程的,这意味着它一次只能处理一个操作。但不要被这点迷惑——它的速度和效率都非常高。
以下是它的工作原理的简化视图:
- 执行同步代码
- 处理定时器(setTimeout, setInterval)
- 处理 I/O 回调
- 处理 setImmediate() 回调
- 关闭回调
- 重复以上步骤
听起来很简单,对吧?不过,当你开始堆积复杂操作时,事情可能会变得棘手。这时,我们的高级模式就派上用场了。
模式 1:工作线程 - 多线程的疯狂
还记得我说过 Node.js 是单线程的吗?其实这并不完全正确。引入工作线程——Node.js 对 CPU 密集型任务的解决方案,否则这些任务会阻塞我们宝贵的事件循环。
以下是如何使用工作线程的一个简单示例:
const { Worker, isMainThread, parentPort } = require('worker_threads');
if (isMainThread) {
const worker = new Worker(__filename);
worker.on('message', (message) => {
console.log('Received:', message);
});
worker.postMessage('Hello, Worker!');
} else {
parentPort.on('message', (message) => {
console.log('Worker received:', message);
parentPort.postMessage('Hello, Main thread!');
});
}
这段代码创建了一个可以与主线程并行运行的工作线程,让你可以卸载繁重的计算任务而不阻塞事件循环。就像为你的 CPU 密集型任务配备了一个私人助理!
何时使用工作线程
- CPU 密集型操作(复杂计算、数据处理)
- 独立任务的并行执行
- 提高同步操作的性能
专业提示:不要过度使用工作线程!它们有开销,所以要明智地使用它们来处理真正受益于并行化的任务。
模式 2:集群 - 因为两个脑袋总比一个好
比一个 Node.js 进程更好的是什么?多个 Node.js 进程!这就是集群的理念。它允许你创建共享服务器端口的子进程,有效地将工作负载分布在多个 CPU 核心上。
以下是一个简单的集群示例:
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
// Fork workers.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
});
} else {
// Workers can share any TCP connection
// In this case, it's an HTTP server
http.createServer((req, res) => {
res.writeHead(200);
res.end('Hello World\n');
}).listen(8000);
console.log(`Worker ${process.pid} started`);
}
这段代码创建了多个工作进程,每个进程都可以处理 HTTP 请求。就像克隆你的服务器,拥有一支小型服务器军队准备处理传入的请求!
集群的好处
- 提高性能和吞吐量
- 更好地利用多核系统
- 增加可靠性(如果一个工作进程崩溃,其他进程可以接管)
记住:能力越大,责任越大。集群可以显著增加应用程序的复杂性,所以在你真正需要水平扩展时使用它。
模式 3:异步迭代器 - 驯服数据流的野兽
在 Node.js 中处理大型数据集或流就像试图从消防水管中喝水。异步迭代器来救场,允许你逐块处理数据,而不会让事件循环不堪重负。
让我们来看一个例子:
const { createReadStream } = require('fs');
const { createInterface } = require('readline');
async function* processFileLines(filename) {
const rl = createInterface({
input: createReadStream(filename),
crlfDelay: Infinity
});
for await (const line of rl) {
yield line;
}
}
(async () => {
for await (const line of processFileLines('huge_file.txt')) {
console.log('Processed:', line);
// Do something with each line
}
})();
这段代码逐行读取一个可能非常大的文件,允许你在不将整个文件加载到内存中的情况下处理每一行。就像为你的数据配备了一条传送带,以可控的速度将其传递给你!
为什么异步迭代器很棒
- 对大型数据集的高效内存使用
- 处理异步数据流的自然方式
- 提高复杂数据处理管道的可读性
综合运用:一个真实的场景
假设我们正在构建一个日志分析系统,需要处理大量日志文件,执行 CPU 密集型计算,并通过 API 提供结果。以下是我们如何结合这些模式:
const cluster = require('cluster');
const { Worker } = require('worker_threads');
const express = require('express');
const { processFileLines } = require('./fileProcessor');
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
// Fork workers for the API server
for (let i = 0; i < 2; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
});
} else {
const app = express();
app.get('/analyze', async (req, res) => {
const results = [];
const worker = new Worker('./analyzeWorker.js');
for await (const line of processFileLines('huge_log_file.txt')) {
worker.postMessage(line);
}
worker.on('message', (result) => {
results.push(result);
});
worker.on('exit', () => {
res.json(results);
});
});
app.listen(3000, () => console.log(`Worker ${process.pid} started`));
}
在这个例子中,我们使用了:
- 集群来创建多个 API 服务器进程
- 工作线程来卸载 CPU 密集型日志分析
- 异步迭代器来高效处理大型日志文件
这种组合使我们能够处理多个并发请求,高效处理大型文件,并执行复杂计算而不阻塞事件循环。就像拥有一台运转良好的机器,每个部分都知道自己的工作,并与其他部分和谐合作!
总结:学到的经验
正如我们所见,在 Node.js 中管理并发性就是要理解事件循环,并知道何时使用高级模式。以下是关键要点:
- 使用工作线程处理会阻塞事件循环的 CPU 密集型任务
- 实现集群以利用多核系统并提高可扩展性
- 利用异步迭代器高效处理大型数据集或流
- 根据你的具体用例战略性地结合这些模式
记住,能力越大,复杂性越大。这些模式是强大的工具,但它们也在调试、状态管理和整体应用程序架构方面引入了新的挑战。明智地使用它们,并始终分析你的应用程序,以确保你确实从这些高级技术中获得了好处。
思考的食粮
当你深入研究 Node.js 并发性时,这里有一些问题供你思考:
- 这些模式如何影响你的应用程序的错误处理和弹性?
- 使用工作线程和生成单独进程之间的权衡是什么?
- 如何有效地监控和调试使用这些高级并发模式的应用程序?
掌握 Node.js 并发性的旅程是持续的,但有了这些模式,你已经在构建快速、高效和可扩展的应用程序的道路上走得很远了。现在,去征服那个事件循环吧!
记住:最好的代码不一定是最复杂的。有时,一个结构良好的单线程应用程序可以胜过一个实现不佳的多线程应用程序。始终根据真实的性能数据进行测量、分析和优化。
编码愉快,愿你的事件循环永远不被打断(除非你希望如此)!