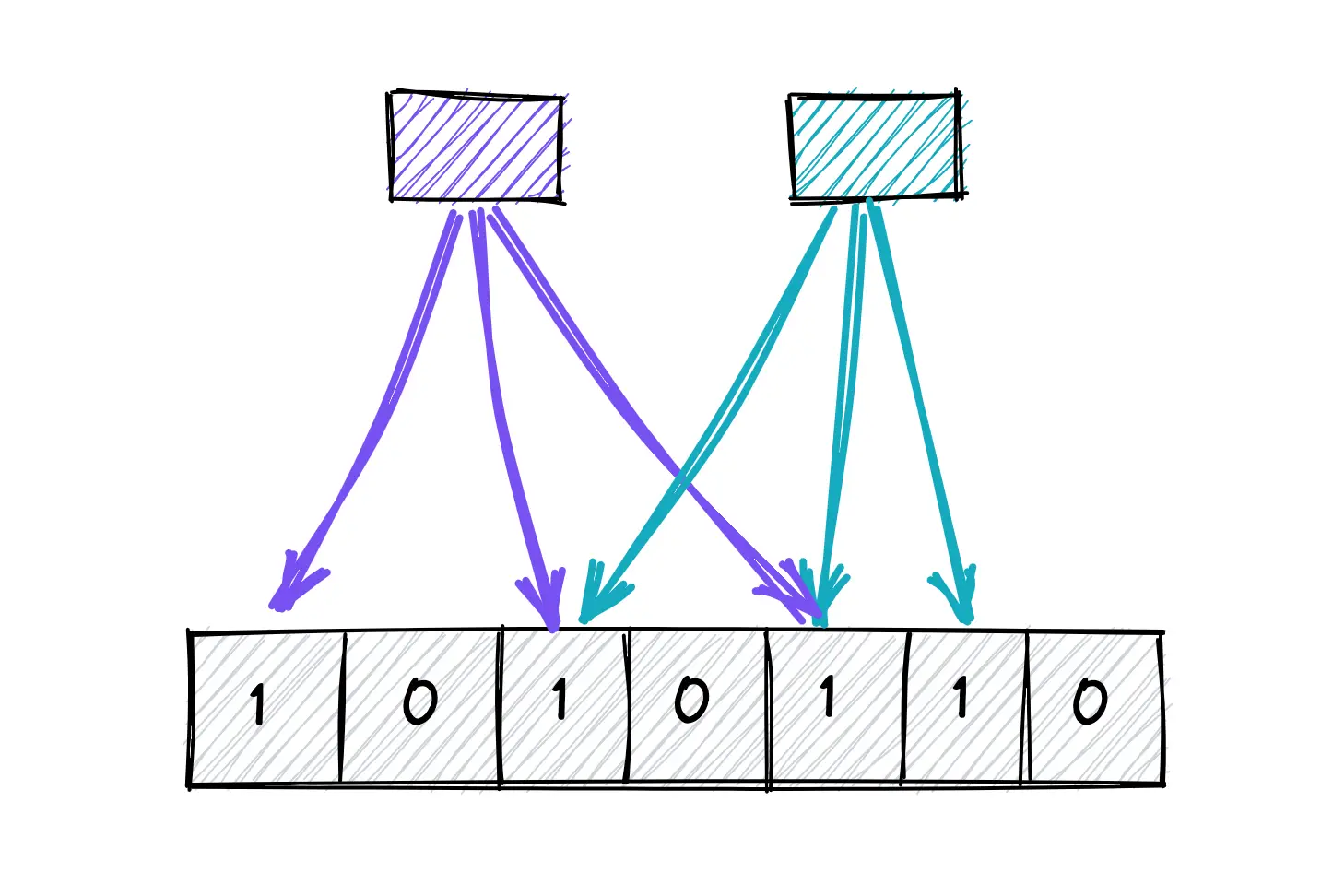
布隆过滤器就像数据世界的保镖——它们能快速告诉你某个东西可能在俱乐部(你的数据集)中,或者绝对不在,而无需真正打开大门。这种概率数据结构可以显著减少不必要的查找和网络调用,使你的系统更快、更高效。
幕后魔法
从本质上讲,布隆过滤器是一个位数组。当你添加一个元素时,它会被多次哈希,并将相应的位设置为1。检查一个元素是否存在时,需要再次对其进行哈希,并查看所有相应的位是否都被设置。这很简单,但非常强大。
class BloomFilter:
def __init__(self, size, hash_count):
self.size = size
self.hash_count = hash_count
self.bit_array = [0] * size
def add(self, item):
for seed in range(self.hash_count):
index = hash(str(seed) + str(item)) % self.size
self.bit_array[index] = 1
def check(self, item):
for seed in range(self.hash_count):
index = hash(str(seed) + str(item)) % self.size
if self.bit_array[index] == 0:
return False
return True
实际应用:布隆过滤器的闪光点
让我们深入探讨一些布隆过滤器可以大显身手的实际场景:
1. 缓存系统:守门员
想象一下你正在运行一个大规模的缓存系统。在访问昂贵的后端存储之前,你可以使用布隆过滤器来检查键可能存在于缓存中。
def get_item(key):
if not bloom_filter.check(key):
return None # 绝对不在缓存中
# 可能在缓存中,让我们检查一下
return actual_cache.get(key)
这个简单的检查可以显著减少缓存未命中和不必要的后端查询。
2. 搜索优化:快速消除器
在分布式搜索系统中,布隆过滤器可以作为预过滤器,消除不必要的跨分片搜索。
def search_shards(query):
results = []
for shard in shards:
if shard.bloom_filter.check(query):
results.extend(shard.search(query))
return results
通过快速消除肯定不包含查询的分片,你可以减少网络流量并提高搜索速度。
3. 重复检测:高效去重器
在抓取网页或处理大数据流时,快速检测重复项至关重要。
def process_item(item):
if not bloom_filter.check(item):
bloom_filter.add(item)
process_new_item(item)
else:
# 可能之前见过,进行额外检查
pass
与保持完整的已处理项目列表相比,这种方法可以显著减少内存占用。
细节:调整你的布隆过滤器
像任何好的工具一样,布隆过滤器需要适当的调整。以下是一些关键考虑因素:
- 大小很重要:过滤器越大,误报率越低,但使用的内存越多。
- 哈希函数:更多的哈希函数可以减少误报,但会增加计算时间。
- 预期项目数量:了解你的数据大小有助于优化过滤器的参数。
这里有一个快速公式来帮助你确定布隆过滤器的大小:
import math
def optimal_bloom_filter_size(item_count, false_positive_rate):
m = -(item_count * math.log(false_positive_rate)) / (math.log(2)**2)
k = (m / item_count) * math.log(2)
return int(m), int(k)
# 示例用法
items = 1000000
fp_rate = 0.01
size, hash_count = optimal_bloom_filter_size(items, fp_rate)
print(f"Optimal size: {size} bits")
print(f"Optimal hash count: {hash_count}")
注意事项和考虑
在你疯狂使用布隆过滤器之前,请记住以下几点:
- 误报是存在的:布隆过滤器可能会说某个项目可能存在而实际上不存在。在错误处理时计划好这一点。
- 无法删除:标准布隆过滤器不支持删除项目。如果你需要这个功能,请查看计数布隆过滤器。
- 不是万能的:虽然强大,但布隆过滤器并不适用于所有场景。仔细评估你的用例。
“能力越大,责任越大。明智地使用布隆过滤器,它们会善待你的后端。” - 本叔叔(如果他是软件架构师的话)
在你的技术栈中集成布隆过滤器
准备好尝试布隆过滤器了吗?以下是一些流行的库,帮助你入门:
更大的图景:为什么要关心?
从宏观上看,布隆过滤器不仅仅是一个聪明的技巧。它们代表了系统设计中的一个更广泛的原则:有时候,一点不确定性可以带来巨大的性能提升。通过接受小概率的误报,我们可以创建更快、更具可扩展性和更高效的系统。
思考的食粮
在你的架构中实现布隆过滤器时,考虑以下问题:
- 布隆过滤器的概率特性如何影响系统设计的其他部分?
- 在哪些其他场景中,牺牲完美的准确性以换取速度是有益的?
- 布隆过滤器的使用如何与系统的SLA和错误预算对齐?
总结:布隆过滤器的魅力
布隆过滤器可能不是城里最新的热门工具,但它们是经过时间考验的、久经沙场的工具,值得在你的后端工具箱中占有一席之地。从缓存到搜索优化,这些概率强者可以为你的分布式系统提供所需的性能提升。
所以,下次你面临数据洪流或查询困境时,请记住:有时候,解决方案就在布隆中。
现在去过滤吧,你们这些了不起的后端大师!