在这次深入探讨中,我们将深入研究高级错误传播机制。我们将探索如何构建一个自定义的容错层,以处理最顽固的错误,使您的分布式系统像诺基亚3310一样坚固,在脆弱的智能手机世界中屹立不倒。
错误传播难题
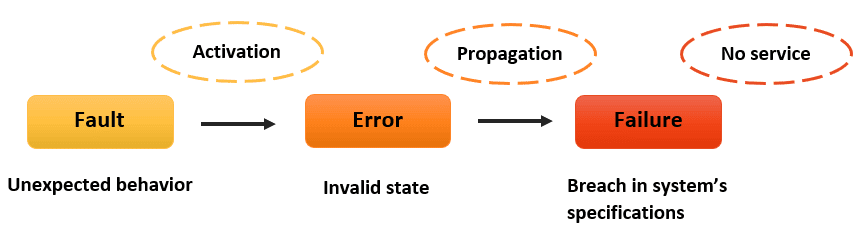
在我们进入解决方案之前,让我们先花点时间了解问题。在分布式系统中,错误就像爱传闲话的邻居——它们传播得很快,如果不加以控制,可能会引起相当大的混乱。
考虑以下场景:
# 服务A
def process_order(order_id):
try:
user = get_user_info(order_id)
items = get_order_items(order_id)
payment = process_payment(user, items)
shipping = arrange_shipping(user, items)
return {"status": "success", "order_id": order_id}
except Exception as e:
return {"status": "error", "message": str(e)}
# 服务B
def get_user_info(order_id):
# 模拟数据库错误
raise DatabaseConnectionError("无法连接到用户数据库")
在这个简单的例子中,服务B中的错误会传递到服务A,可能导致一连串的故障。但如果我们能够拦截这些错误,分析它们,并智能地响应呢?这就是我们自定义容错层的用武之地。
构建容错层
我们的容错层将由几个关键组件组成:
- 错误分类系统
- 传播规则引擎
- 断路器实现
- 带指数退避的重试机制
- 回退策略
让我们逐一分解这些组件。
1. 错误分类系统
第一步是根据错误的严重性和潜在影响对其进行分类。我们将创建一个自定义错误层次结构:
class BaseError(Exception):
def __init__(self, message, severity):
self.message = message
self.severity = severity
class TransientError(BaseError):
def __init__(self, message):
super().__init__(message, severity="LOW")
class PartialOutageError(BaseError):
def __init__(self, message):
super().__init__(message, severity="MEDIUM")
class CriticalError(BaseError):
def __init__(self, message):
super().__init__(message, severity="HIGH")
这种分类允许我们根据错误的严重性以不同的方式处理它们。
2. 传播规则引擎
接下来,我们将创建一个规则引擎来决定错误应如何在我们的系统中传播:
class PropagationRulesEngine:
def __init__(self):
self.rules = {
TransientError: self.handle_transient,
PartialOutageError: self.handle_partial_outage,
CriticalError: self.handle_critical
}
def handle_error(self, error):
handler = self.rules.get(type(error), self.default_handler)
return handler(error)
def handle_transient(self, error):
# 实现重试逻辑
pass
def handle_partial_outage(self, error):
# 实现回退策略
pass
def handle_critical(self, error):
# 实现断路
pass
def default_handler(self, error):
# 记录并传播
logging.error(f"未处理的错误: {error}")
raise error
这个引擎允许我们为不同的错误类型定义特定的行为。
3. 断路器实现
为了防止级联故障,我们将实现一个断路器模式:
import time
class CircuitBreaker:
def __init__(self, failure_threshold, reset_timeout):
self.failure_count = 0
self.failure_threshold = failure_threshold
self.reset_timeout = reset_timeout
self.last_failure_time = None
self.state = "CLOSED"
def execute(self, func, *args, **kwargs):
if self.state == "OPEN":
if time.time() - self.last_failure_time > self.reset_timeout:
self.state = "HALF-OPEN"
else:
raise CircuitBreakerOpenError("电路已打开")
try:
result = func(*args, **kwargs)
if self.state == "HALF-OPEN":
self.state = "CLOSED"
self.failure_count = 0
return result
except Exception as e:
self.failure_count += 1
if self.failure_count >= self.failure_threshold:
self.state = "OPEN"
self.last_failure_time = time.time()
raise e
这个断路器将在发生一定数量的故障时自动“跳闸”,防止进一步调用有问题的服务。
4. 带指数退避的重试机制
对于瞬态错误,带指数退避的重试机制非常有用:
import random
import time
def retry_with_backoff(retries=3, backoff_in_seconds=1):
def decorator(func):
def wrapper(*args, **kwargs):
x = 0
while True:
try:
return func(*args, **kwargs)
except TransientError as e:
if x == retries:
raise e
sleep = (backoff_in_seconds * 2 ** x +
random.uniform(0, 1))
time.sleep(sleep)
x += 1
return wrapper
return decorator
@retry_with_backoff(retries=5, backoff_in_seconds=1)
def unreliable_function():
# 模拟不可靠的函数
if random.random() < 0.7:
raise TransientError("临时故障")
return "成功!"
这个装饰器将自动重试函数,并在尝试之间增加延迟。
5. 回退策略
最后,让我们实现一些在所有方法都失败时的回退策略:
class FallbackStrategy:
def __init__(self):
self.strategies = {
"get_user_info": self.fallback_user_info,
"process_payment": self.fallback_payment,
"arrange_shipping": self.fallback_shipping
}
def execute_fallback(self, function_name, *args, **kwargs):
fallback = self.strategies.get(function_name)
if fallback:
return fallback(*args, **kwargs)
raise NoFallbackError(f"没有{function_name}的回退策略")
def fallback_user_info(self, order_id):
# 返回缓存或默认用户信息
return {"user_id": "default", "name": "John Doe"}
def fallback_payment(self, user, items):
# 将付款标记为待处理并继续
return {"status": "pending", "message": "付款将稍后处理"}
def fallback_shipping(self, user, items):
# 使用默认的运输方式
return {"method": "standard", "estimated_delivery": "5-7个工作日"}
这些回退策略在正常操作失败时提供了一个安全网。
整合所有组件
现在我们有了所有的组件,让我们看看它们如何在我们的分布式系统中协同工作:
class FaultToleranceLayer:
def __init__(self):
self.rules_engine = PropagationRulesEngine()
self.circuit_breaker = CircuitBreaker(failure_threshold=5, reset_timeout=60)
self.fallback_strategy = FallbackStrategy()
def execute(self, func, *args, **kwargs):
try:
return self.circuit_breaker.execute(func, *args, **kwargs)
except Exception as e:
try:
return self.rules_engine.handle_error(e)
except Exception:
return self.fallback_strategy.execute_fallback(func.__name__, *args, **kwargs)
# 使用容错层
fault_tolerance = FaultToleranceLayer()
@retry_with_backoff(retries=3, backoff_in_seconds=1)
def get_user_info(order_id):
# 实际实现
pass
def process_order(order_id):
user = fault_tolerance.execute(get_user_info, order_id)
# 订单处理逻辑的其余部分
pass
通过这种设置,我们的系统可以优雅地处理各种错误场景,防止级联故障并提高整体可靠性。
回报:更具弹性的系统
通过实现这个自定义容错层,我们显著提高了分布式系统的弹性。我们获得了以下好处:
- 基于错误类型和严重性的智能错误处理
- 对瞬态故障的自动重试
- 通过断路器防止级联故障
- 通过回退策略实现优雅降级
- 提高对错误模式和系统行为的可见性
请记住,构建容错分布式系统是一个持续的过程。持续监控系统的行为,完善错误处理策略,并适应新出现的故障模式。
思考题
在实现自己的容错层时,请考虑以下问题:
- 如何处理不符合分类系统的错误?
- 您将使用哪些指标来评估容错机制的有效性?
- 如何在追求弹性和系统响应性之间取得平衡?
- 如何利用这个容错层来提高系统的可观测性?
请记住,在分布式系统的世界中,错误不仅是不可避免的——它们是让您的系统更强大的机会。祝您错误处理愉快!