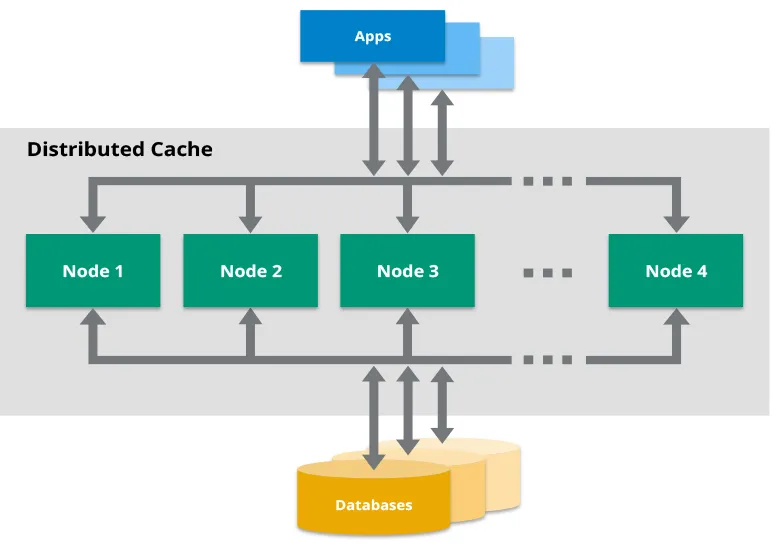
为什么选择Hazelcast?为什么你应该关心?
在我们深入探讨之前,先来解决一个问题:为什么选择Hazelcast?在众多缓存解决方案中,Hazelcast作为一个分布式内存数据网格脱颖而出,它与Java完美结合。它就像Redis,但采用Java优先的方法,并具备一些巧妙的功能,使得在微服务中实现分布式缓存变得轻而易举。
以下是Hazelcast可能成为你新宠的几个原因:
- 原生Java API(不再需要处理序列化问题)
- 分布式计算(想象一下MapReduce,但更简单)
- 内置分裂脑保护(因为网络分区是不可避免的)
- 轻松扩展(只需添加更多节点)
在你的微服务中设置Hazelcast
让我们从基础开始。将Hazelcast添加到你的Java微服务中其实非常简单。首先,将依赖项添加到你的pom.xml中:
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>5.1.1</version>
</dependency>
现在,让我们创建一个简单的Hazelcast实例:
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
public class CacheConfig {
public HazelcastInstance hazelcastInstance() {
return Hazelcast.newHazelcastInstance();
}
}
瞧!你现在在你的微服务中运行了一个Hazelcast节点。但等等,还有更多!
高级缓存模式
现在我们已经掌握了基础知识,让我们深入探讨一些能让你的微服务更高效的高级缓存模式。
1. 读通/写通缓存
这种模式就像为你的数据配备了一个私人助理。Hazelcast可以为你自动管理缓存中的数据,而不是手动操作。
public class UserCacheStore implements MapStore<String, User> {
@Override
public User load(String key) {
// 从数据库加载
}
@Override
public void store(String key, User value) {
// 存储到数据库
}
// 其他方法...
}
MapConfig mapConfig = new MapConfig("users");
mapConfig.setMapStoreConfig(new MapStoreConfig().setImplementation(new UserCacheStore()));
Config config = new Config();
config.addMapConfig(mapConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
通过这种设置,Hazelcast会在缓存中没有数据时自动从数据库加载数据,并在缓存中更新数据时将其写回数据库。这就像魔法,但更好,因为这实际上是优秀的工程设计。
2. 近缓存模式
有时候,即使在分布式环境中,你也需要数据快速响应。近缓存模式就是为此而生。它就像为你的缓存再加一层缓存。很酷吧?
NearCacheConfig nearCacheConfig = new NearCacheConfig();
nearCacheConfig.setName("users");
nearCacheConfig.setTimeToLiveSeconds(300);
MapConfig mapConfig = new MapConfig("users");
mapConfig.setNearCacheConfig(nearCacheConfig);
Config config = new Config();
config.addMapConfig(mapConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
这种设置在每个Hazelcast节点上创建一个本地缓存,减少网络调用并加速读取操作。对于那些频繁读取但很少更新的数据,这尤其有用。
3. 驱逐策略
内存是宝贵的,尤其是在微服务中。Hazelcast提供了复杂的驱逐策略,以确保你的缓存不会占用过多内存。
MapConfig mapConfig = new MapConfig("users");
mapConfig.setEvictionConfig(
new EvictionConfig()
.setEvictionPolicy(EvictionPolicy.LRU)
.setMaxSizePolicy(MaxSizePolicy.PER_NODE)
.setSize(10000)
);
Config config = new Config();
config.addMapConfig(mapConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
此配置设置了一个LRU(最近最少使用)驱逐策略,确保你的缓存在每个节点上保持在10000个条目以内。就像为你的数据派对安排了一个保镖,当人满为患时,踢出最不受欢迎的条目。
分布式计算:更上一层楼
缓存很棒,但Hazelcast能做的更多。让我们看看如何利用分布式计算来增强我们的微服务。
1. 分布式执行服务
需要在整个集群中运行任务?Hazelcast的分布式执行服务可以满足你的需求。
public class UserAnalytics implements Callable<Map<String, Integer>>, HazelcastInstanceAware {
private transient HazelcastInstance hazelcastInstance;
@Override
public Map<String, Integer> call() {
IMap<String, User> users = hazelcastInstance.getMap("users");
// 在本地数据上执行分析
return results;
}
@Override
public void setHazelcastInstance(HazelcastInstance hazelcastInstance) {
this.hazelcastInstance = hazelcastInstance;
}
}
HazelcastInstance hz = Hazelcast.newHazelcastInstance();
IExecutorService executorService = hz.getExecutorService("analytics-executor");
Set<Member> members = hz.getCluster().getMembers();
Map<Member, Future<Map<String, Integer>>> results = executorService.submitToMembers(new UserAnalytics(), members);
// 聚合结果
Map<String, Integer> finalResults = new HashMap<>();
for (Future<Map<String, Integer>> future : results.values()) {
Map<String, Integer> result = future.get();
// 合并结果到finalResults
}
这种模式允许你在数据所在的位置运行计算,减少数据移动并提高性能。就像把函数带到数据,而不是相反。
2. 条目处理器
需要原子地更新缓存中的多个条目?条目处理器是你的好帮手。
public class UserUpgradeEntryProcessor implements EntryProcessor<String, User, Object> {
@Override
public Object process(Map.Entry<String, User> entry) {
User user = entry.getValue();
if (user.getPoints() > 1000) {
user.setStatus("GOLD");
entry.setValue(user);
}
return null;
}
}
IMap<String, User> users = hz.getMap("users");
users.executeOnEntries(new UserUpgradeEntryProcessor());
这种模式允许你在多个条目上执行操作,而无需显式锁定或事务管理。就像为缓存中的每个条目提供了一个小型事务。
需要注意的陷阱
与任何强大的工具一样,Hazelcast也有其潜在的陷阱。以下是一些需要注意的事项:
- 过度缓存:并不是所有东西都需要缓存。要选择性地将数据放入Hazelcast。
- 忽视序列化:Hazelcast需要序列化对象。确保你的对象是可序列化的,并为复杂对象考虑自定义序列化器。
- 忽略监控:为你的Hazelcast集群设置适当的监控。像Hazelcast管理中心这样的工具非常有价值。
- 忽视一致性:在分布式系统中,最终一致性通常是常态。根据这一点设计你的应用程序。
总结
我们已经涵盖了很多内容,从基础设置到高级缓存模式和分布式计算。Hazelcast是一个强大的工具,可以显著提升你的Java微服务的性能和可扩展性。但请记住,能力越大,责任越大。明智地使用这些模式,并始终考虑你的应用程序的具体需求。
现在,去像专业人士一样缓存吧!你的微服务(和你的用户)会感谢你。
“最快的数据访问是不需要访问的数据。” - 未知缓存大师(可能)
进一步阅读
如果你想了解更多,请查看以下资源:
祝你缓存愉快!